
Шаблоны мультиагентных систем
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 58
Цикл самосовершенствования (аналогия RLHF)
Агент, которого мы создаём сегодня, останется тем же самым агентом и завтра.
Для создания системы, которая действительно учится и совершенствуется со временем, нам необходим цикл самосовершенствования .
Эта архитектура имитирует цикл обучения человека do -> get feedback -> improve. Мы создадим рабочий процесс, в котором результаты работы агента будут немедленно оценены, и если они окажутся недостаточно хорошими, агент будет вынужден пересмотреть свою работу на основе конкретной обратной связи.
Это ключ к достижению экспертного уровня производительности в любой системе распознавания/обучения агентов. Именно так вы обучаете агента, чтобы он перешел от неплохого базового уровня к первоклассному исполнителю. Сохраняя лучшие, проверенные результаты, вы создаете «золотой стандарт» данных, который служит основой для всей будущей работы, формируя систему, которая учится на своих успехах.
Простой процесс RLHF для агентов работает следующим образом…
Нажмите Enter или щелкните, чтобы просмотреть изображение в полном размере.
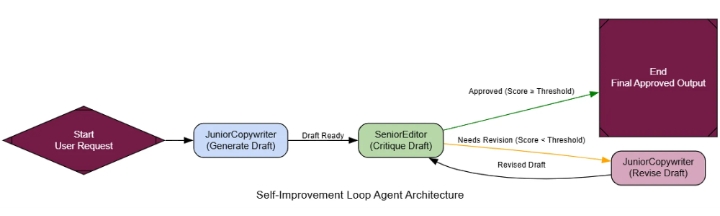
Процесс RLHF
Создание первоначального результата: «младший» агент создает первый черновик.
Результат критики: Опытный критик оценивает черновик по строгой системе критериев.
Решение: Система проверяет, соответствует ли оценка рецензии пороговому значению качества.
Пересмотр (цикл): Если оценка слишком низкая, первоначальный вариант и отзывы критика передаются обратно младшему агенту для создания пересмотренной версии.
Принятие: После подтверждения вывода цикл завершается.
Мы создадим JuniorCopywriterагента для генерации маркетинговых писем и SeniorEditorагента для их анализа. Ключевым моментом является структурированный результат анализа, предоставляющий полезную обратную связь.
class MarketingEmail ( BaseModel ):
"""Представляет собой черновик маркетингового письма."""
subject: str = Field(description= "Запоминающаяся и лаконичная тема письма." )
body: str = Field(description= "Полный текст письма, написанный в формате Markdown." )
class Critique ( BaseModel ):
"""Структурированная критика черновика маркетингового письма."""
score: int = Field(description= "Общая оценка качества от 1 (плохо) до 10 (отлично)." )
feedback_points: List [ str ] = Field(description= "Маркированный список конкретных, действенных пунктов обратной связи для улучшения." )
is_approved: bool = Field(description= "Логическое значение, указывающее, одобрен ли черновик (оценка >= 8). Это дублирует оценку, но полезно для маршрутизации." )
# --- 1. Генератор: Младший копирайтер ---
def get_generator_chain ():
prompt = ChatPromptTemplate.from_messages([
( "system" , "Вы — начинающий копирайтер в сфере маркетинга. Ваша задача — написать первый черновик маркетингового письма на основе запроса пользователя. Проявите креативность, но сосредоточьтесь на донесении основной мысли." ),
( "human" , "Напишите маркетинговое письмо на следующую тему:\n\n{request}" ) ]
)
return prompt | llm.with_structured_output(MarketingEmail)
# --- 2. Критик: Старший редактор ---
def get_critic_chain ():
prompt = ChatPromptTemplate.from_messages([
( "system" , """Вы — старший редактор по маркетингу и бренд-менеджер. Ваша задача — оценить черновик электронного письма, написанный младшим копирайтером.
Оцените черновик по следующим критериям:
1. **Запоминающаяся тема:** Является ли тема письма привлекательной и вероятно ли, что оно будет открыто?
2. **Ясность и убедительность:** Является ли основной текст ясным, убедительным и убедительным?
3. **Сильный призыв к действию (CTA):** Есть ли четкое, единственное действие, которое должен совершить пользователь?
4. **Тон бренда:** Является ли тон профессиональным, но в то же время доступным?
Присвойте оценку от 1 до 10. Оценка 8 или выше означает, что черновик одобрен для отправки. Предоставьте конкретные,
"Полезная обратная связь, которая поможет автору улучшить свои навыки."" ),
("человек" , "Пожалуйста, оцените следующий черновик электронного письма:\n\n**Тема:** {тема}\n\n**Текст:**\n{текст}" )
])
return prompt | llm.with_structured_output(Critique)
# --- 3. Редактор (Генератор в режиме «Редактировать») ---
def get_reviser_chain ():
prompt = ChatPromptTemplate.from_messages([
( "system" , "Вы — младший копирайтер, написавший первоначальный черновик. Вы только что получили отзыв от старшего редактора. Ваша задача — тщательно отредактировать черновик, чтобы учесть каждый пункт отзыва. Создайте новую, улучшенную версию письма." ),
( "human" , "Первоначальный запрос: {request}\n\nВот ваш первоначальный черновик:\n**Тема:** {original_subject}\n**Текст:**\n{original_body}\n\nВот отзыв от вашего редактора:\n{feedback}\n\nПожалуйста, предоставьте отредактированное письмо." )
])
return prompt | llm.with_structured_output(MarketingEmail)
Теперь нам нужно просто подключить это в LangGraph с помощью условного ребра, которое проверяет is_approvedфлаг из критической оценки. Если он равен False, мы возвращаемся к revise_node.
# ... (определение состояния) ...
def should_continue ( state: AgentState ) -> str :
"""Проверяет критику, чтобы решить, зацикливаться или завершать."""
if state[ 'critique' ].is_approved:
return "end"
if state[ 'revision_number' ] >= 3 : # Максимальный лимит ревизий
return "end"
else :
return "continue"
workflow = StateGraph(AgentState)
workflow.add_node( "generate" , generate_node)
workflow.add_node( "critique" , critique_node)
workflow.add_node( "revise" , revise_node)
workflow.set_entry_point( "generate" )
workflow.add_edge( "generate" , "critique" )
workflow.add_conditional_edges( "critique" , should_continue, { "continue" : "revise" , " end" : END})
workflow.add_edge( "revise" , "critique" )
self_refine_agent = workflow.compile ()
RlHF
Давайте дадим ему задание и посмотрим, как оно будет учиться.
request = "Написать маркетинговое письмо для нашей новой платформы обработки данных на основе ИИ, 'InsightSphere'."
final_result = run_agent(request) # Предполагается, что run_agent передает процесс в потоковом режиме
На графике выходных данных показано, как агент обучается в режиме реального времени.
--- Шаг: Создание ---
Черновик 1
Тема: Анонс нового продукта
Текст: Мы рады объявить о нашем новом продукте, InsightSphere... ---
Шаг: Критика (Редакция №1) ---
Оценка результата критики
: 4/10 Отзыв: - Тема слишком общая . - Текст слишком упрощенный ... - Призыв к действию слабый . --- Шаг: Редактирование --- Черновик 2 Тема: Раскройте истинный потенциал ваших данных с помощью InsightSphere Текст: Вам сложно превратить огромные массивы данных в полезные аналитические выводы? Мы рады представить **InsightSphere**... --- Шаг: Критика (Редакция №2) --- Оценка результата критики : 9/10 Отзыв: - Отличная работа над редакцией. Одобрено .
Агент взял ужасный первый черновик и, руководствуясь замечаниями редактора, превратил его в высококачественный маркетинговый текст.
Для формализации этого процесса нашему магистру права, выступающему в роли судьи, необходимо оценивать качество работы.
class QualityImprovementEvaluation ( BaseModel ):
initial_quality_score: int = Field(description= "Оценка от 1 до 10 качества первоначального варианта." )
final_quality_score: int = Field(description= "Оценка от 1 до 10 качества окончательного, переработанного варианта." )
justification: str = Field(description= "Краткое обоснование оценок с указанием улучшений." )
При оценке улучшения очевидны.
--- Оценка процесса самосовершенствования ---
{
'initial_quality_score': 3,
'final_quality_score': 9,
'justification': "Агент продемонстрировал значительное улучшение. Первоначальный черновик был общим и неэффективным. Окончательная версия, после учета критики, оказалась убедительной, хорошо структурированной и содержала сильный призыв к действию. Цикл самосовершенствования был весьма успешным."
}
Хотя показатель качества не очень высок, в нашем процессе четко прослеживается следующее…
Благодаря этому циклу самообучения мы можем улучшить результаты работы агента, переведя их из удовлетворительного состояния в отличное , и с каждым раундом добиваться лучших результатов.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 50
Память графа (мировой модели)
Таким образом, последний агент способен запоминать информацию, что является неплохим шагом вперед в области персонализации. Но его память все еще несколько разрознена. Он может вспомнить, что разговор состоялся (эпизодический эффект) и что существует факт (семантический эффект)…
но ему трудно понять сложную сеть взаимосвязей между всеми известными ему фактами.
Архитектура памяти на основе графов (мировой модели) решает эту проблему.
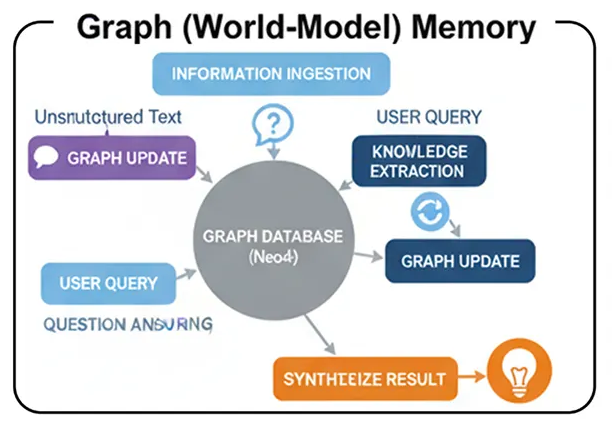
Вместо простого хранения фактов, этот агент строит структурированную, взаимосвязанную «модель мира» своих знаний. Он обрабатывает неструктурированный текст и преобразует его в богатый граф знаний, состоящий из сущностей (узлов) и отношений (ребер) .
В крупномасштабной системе искусственного интеллекта именно так строится настоящий «мозг». Это основа любой системы, которой необходимо отвечать на сложные, многоступенчатые вопросы, требующие соединения разрозненных фрагментов информации. Представьте себе корпоративную систему интеллекта, которой необходимо понимать взаимосвязи между компаниями, сотрудниками и продуктами на основе тысяч документов.
Давайте разберемся, как протекает этот процесс.
Нажмите Enter или щелкните, чтобы просмотреть изображение в полном размере.
 .
.
Графовая память (создано с помощью)
Фарид Хан
)
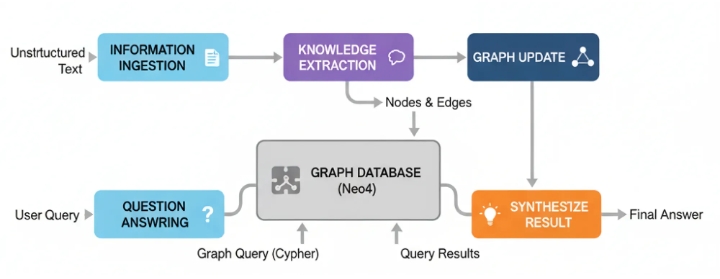
Всасывание информации: Агент читает неструктурированный текст (например, новостные статьи или отчеты).
Извлечение знаний: Процесс, основанный на LLM, анализирует текст, выявляя ключевые сущности и взаимосвязи между ними.
Обновление графа: извлеченные узлы и ребра добавляются в постоянную базу данных графов, например, Neo4j.
Ответы на вопросы: Когда пользователю задают вопрос, агент преобразует его запрос в формальный запрос к графу (подобно Cypher), выполняет его и синтезирует результаты в ответ.
В основе этой системы лежит агент «Graph Maker». Его задача — прочитать блок текста и выдать структурированный список сущностей и связей. Мы будем использовать Pydantic, чтобы убедиться, что его вывод будет чистым и готовым для нашей базы данных.
# Модели Pydantic для структурированного извлечения
class Node ( BaseModel ):
id : str = Field(description= "Уникальное имя или идентификатор сущности." )
type : str = Field(description= "Тип сущности (например, Человек, Компания)." )
class Relationship ( BaseModel ):
source: Node
target: Node
type : str = Field(description= "Тип отношения (например, WORKS_FOR, ACQUIRED)." )
class KnowledgeGraph ( BaseModel ):
relationships: List [Relationship]
def get_graph_maker_chain ():
"""Создает агента, ответственного за извлечение знаний."""
extractor_llm = llm.with_structured_output(KnowledgeGraph)
prompt = ChatPromptTemplate.from_messages([
( "system" , "Вы эксперт в извлечении информации. Извлеките все сущности и отношения из предоставленного текста. Тип отношения должен быть глаголом во всех заглавными буквами, например, 'WORKS_FOR'." ),
( "human" , "Извлеките граф знаний из следующего текста:\n\n{text}" )
])
return prompt | extractor_llm
graph_maker_age= get_graph_maker_chain()

Мировая модель памяти (создана)
Фарид Хан
)
Далее нам нужен агент, способный запрашивать данные из этого графа. Это включает в себя процесс преобразования текста в шифр , в ходе которого агент преобразует вопрос на естественном языке в запрос к базе данных.
def query_graph ( question: str ) -> Dict [ str , Any ]:
"""Полный конвейер преобразования текста в Cypher и синтеза."""
console. print ( f"\n[bold]Вопрос:[/bold] {question} " )
# 1. Генерация запроса Cypher с использованием схемы графа
cypher_chain = llm # Упрощенная цепочка
generated_cypher = cypher_chain.invoke( f"Преобразовать этот вопрос в запрос Cypher, используя эту схему: {graph.schema} \nВопрос: {question} " ).content
console. print ( f"[cyan]Сгенерированный шифр:\n {generated_cypher} [/cyan]" )
# 2. Выполнение запроса Cypher
context = graph.query(generated_cypher) # Предполагая, что 'graph' — это наше соединение Neo4j
# 3. Синтез окончательного ответа
synthesis_chain = llm # Упрощенная цепочка
answer = synthesis_chain.invoke( f"Ответьте на этот вопрос: {question} \nИспользуя эти данные: {context} " ).content
return { "answer" : answer}
Теперь перейдём к решающему тесту. Мы передадим нашему агенту три отдельных фрагмента текста. Стандартный агент RAG воспринял бы их как несвязанные между собой части. Наш агент, работающий с графами, поймет скрытые связи.
unstructured_documents = [
"AlphaCorp объявила о приобретении стартапа BetaSolutions." ,
"Доктор Эвелин Рид — главный научный сотрудник AlphaCorp." ,
"Флагманский продукт Innovate Inc., NeuraGen, конкурирует с искусственным интеллектом QuantumLeap от AlphaCorp."
]
# Теперь зададим многошаговый вопрос
query_graph( "Кто работает в компании, которая приобрела BetaSolutions?" )
Стандартный агент с этим бы с треском провалился. Однако наш агент, работающий с графами, справляется с задачей на отлично. Трассировка выходных данных демонстрирует его логику:
Вопрос: Кто работает в компании, которая приобрела BetaSolutions?
--- ➡️ Генерация запроса Cypher ---
[cyan]Сгенерированный Cypher:
MATCH (p:Person)-[:WORKS_FOR]->(c:Company)-[:ACQUIRED]->(:Company {id: 'BetaSolutions'}) RETURN p.id
[/cyan]
--- ⚡ Выполнение запроса ---
[yellow]Результат запроса:
[{'p.id': 'Dr. Evelyn Reed'}]
[/yellow]
--- 🗣️ Синтез окончательного ответа ---
Окончательный ответ: Доктор Эвелин Рид работает в компании, которая приобрела BetaSolutions, а именно в AlphaCorp.
Агент успешно прошёл по графу: от BetaSolutions, он нашёл AlphaCorpчерез ACQUIREDребро, а затем нашёл Dr. Evelyn Reedчерез WORKS_FORребро. Это рассуждение невозможно без структурированной модели мира.
Для формализации этого, наш магистр права в качестве судьи должен оценивать аргументацию, основанную на многоступенчатом анализе.
class MultiHopEvaluation ( BaseModel ):
multi_hop_accuracy_score: int = Field(description= "Оценка от 1 до 10, показывающая, правильно ли агент связал несколько фрагментов информации для ответа на вопрос." )
justification: str = Field(description= "Краткое обоснование оценки." )
По результатам оценки, графический агент получает хорошую оценку в 7 баллов (выше среднего, на мой взгляд).
--- Оценка логики работы агента графа ---
{
'multi_hop_accuracy_score': 7,
'justification': "Агент продемонстрировал безупречную логику работы с несколькими шагами. Он правильно определил компанию-покупателя на основе одного факта, а затем использовал эту информацию для поиска сотрудника на основе совершенно другого факта. Это демонстрирует глубокое, взаимосвязанное понимание базы знаний."
}
Мы видим, что, создавая структурированную модель мира, мы наделяем наших агентов способностью рассуждать, а не просто извлекать информацию.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 45
Принятие решений коллективом
Пока что у всех наших агентов, даже у команд, есть одна общая черта: они выстраивают единую цепочку рассуждений.
Но LLM-ы — это недетерминированные системы, если запустить один и тот же запрос дважды, можно получить немного разные ответы.
Это может стать проблемой в ситуациях с высокими ставками, когда вам нужен надежный и всесторонний ответ.
Архитектура ансамблевого принятия решений решает эту проблему напрямую. Она основана на принципе «мудрости толпы».
Вместо того чтобы полагаться на одного агента, мы запускаем параллельно несколько независимых агентов, часто с разными «характеристиками», а затем используем заключительного агента-агрегатора для синтеза их результатов в единый, более надежный вывод.
В крупномасштабной системе искусственного интеллекта это основной подход для любой критически важной задачи поддержки принятия решений. Вспомните инвестиционный комитет по ИИ или систему медицинской диагностики. Получение «второго мнения» (или третьего, или четвертого) от разных ИИ-персонажей значительно снижает вероятность того, что предвзятость или иллюзия одного агента приведут к неблагоприятному результату.
Давайте разберемся, как протекает этот процесс.
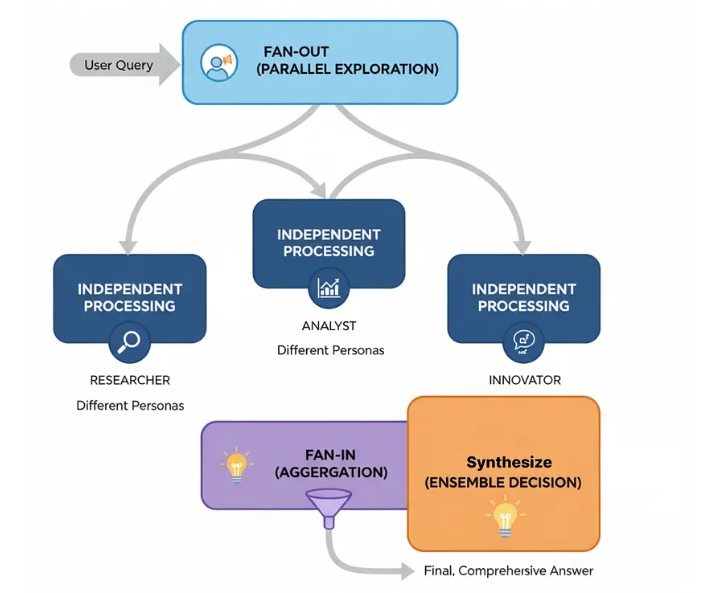
Ансамбль (создан)
Фарид Хан
)
Параллельное исследование (Fan-Out): Запрос пользователя одновременно отправляется нескольким агентам-специалистам. Этим агентам назначаются разные роли, чтобы стимулировать нестандартное мышление.
Независимая обработка: Каждый агент работает над проблемой изолированно, генерируя собственный полный анализ.
Агрегация (Fan-In): Собираются выходные данные от всех агентов.
Синтез (решение на основе совокупности мнений): Конечный агент-«агрегатор» получает все отдельные отчеты, взвешивает различные точки зрения и синтезирует исчерпывающий окончательный ответ.
Ключ к успешной работе ансамбля — когнитивное разнообразие. Мы создадим трёх агентов-аналитиков, каждый с совершенно разным характером: Bullish Growth Analyst(оптимист), Cautious Value Analyst(скептик) и Quantitative Analyst(сторонник строгих стандартов обработки данных).
class EnsembleState ( TypedDict ):
query: str
analyses: Dict [ str , str ] # Сохраняем выходные данные каждого параллельного агента
final_recommendation: Optional [ Any ]
# Мы снова воспользуемся нашей фабрикой специалистов, но с совершенно другими персонами
bullish_persona = "Аналитик, настроенный оптимистично: Вы чрезвычайно оптимистичны в отношении технологий и инноваций. Сосредоточьтесь на будущем потенциале роста и преуменьшите краткосрочные риски."
bullish_analyst_node = create_specialist_node(bullish_persona, "BullishAnalyst" )
value_persona = "Осторожный аналитик, ориентированный на стоимость: Вы скептически настроенный инвестор, сосредоточенный на фундаментальных показателях и риске. Тщательно изучайте финансовые показатели, конкуренцию и потенциальные сценарии снижения стоимости."
value_analyst_node = create_specialist_node(value_persona, "ValueAnalyst" )
quant_persona = "Количественный аналитик (Quant): Вы руководствуетесь исключительно данными. Игнорируйте описания и сосредоточьтесь только на конкретных цифрах, таких как финансовые показатели и технические индикаторы."
quant_analyst_node = create_specialist_node(quant_persona, "QuantAnalyst" )
Последний и самый важный элемент — это наш агрегатор cio_synthesizer_node. Его задача — обработать эти противоречивые отчеты и составить единую, сбалансированную инвестиционную концепцию.
class FinalRecommendation ( BaseModel ):
"""Окончательный, синтезированный инвестиционный тезис от директора по инвестициям."""
final_recommendation: str
confidence_score: float
synthesis_summary: str
identified_opportunities: List [ str ]
identified_risks: List [ str ]
def cio_synthesizer_node ( state: EnsembleState ) -> Dict [ str , Any ]:
"""Заключительный узел, который синтезирует все анализы в единую рекомендацию."""
console. print ( "--- 🏛️ Звонок главному инвестиционному директору для принятия окончательного решения ---" )
all_analyses = "\n\n---\n\n" .join( ["**Анализ от {name} :**\n {analysis} " for name, analysis in state[ 'analyses' ].items()])
cio_prompt = ChatPromptTemplate.from_messages([
" system" , "Вы — главный инвестиционный директор. Ваша задача — синтезировать эти разнообразные и часто противоречащие друг другу точки зрения в единый, окончательный и действенный инвестиционный тезис. Взвесьте потенциал роста против рисков, чтобы прийти к сбалансированному выводу." ),
( "human" , "Вот отчеты вашей команды по запросу: '{query}'\n\n{analyses}\n\nПредоставьте свой окончательный, синтезированный инвестиционный тезис." )
])
cio_llm = llm.with_structured_output(FinalRecommendation)
chain = cio_prompt | cio_llm
final_decision = chain.invoke({ "query" : state[ 'query' ], "analyses" : all_analyses})
return { "final_recommendation" : final_decision}
Теперь давайте подключим его. LangGraph для этого уникален тем, что имеет «разветвление» , где один узел разветвляется на три параллельных узла, а затем «вход», где эти три узла сходятся на конечном синтезаторе.
workflow = StateGraph(EnsembleState)
# Входной узел просто подготавливает состояние
workflow.add_node( "start_analysis" , lambda state: { "analyses" : {}})
# Добавляем параллельные узлы аналитика и финальный синтезатор
workflow.add_node( "bullish_analyst" , bullish_analyst_node)
workflow.add_node( "value_analyst" , value_analyst_node)
workflow.add_node( "quant_analyst" , quant_analyst_node)
workflow.add_node( "cio_synthesizer" , cio_synthesizer_node)
workflow.set_entry_point( "start_analysis" )
# FAN-OUT: Запускаем все три аналитика параллельно
workflow.add_edge( "start_analysis" , [ "bullish_analyst" , "value_analyst" , "quant_analyst" ])
# ВХОД: После завершения работы всех аналитиков вызовите синтезатор
workflow.add_edge([ "bullish_analyst" , "value_analyst" , "quant_analyst" ], "cio_synthesizer" )
workflow.add_edge( "cio_synthesizer" , END)
ensemble_agent = workflow.compile ( )
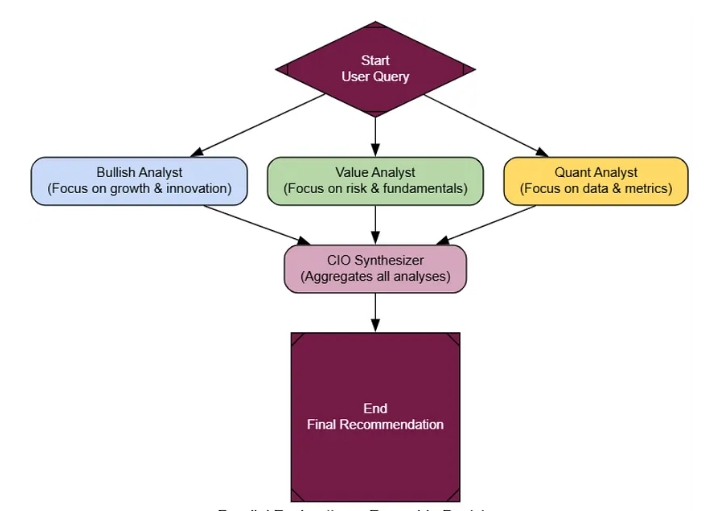
Ансамбль (создан)
Фарид Хан
)
Давайте зададим нашему инвестиционному комитету сложный, неоднозначный вопрос, по которому ценны разные точки зрения.
запрос = "Судя по последним новостям, финансовым показателям и перспективам на будущее, является ли NVIDIA (NVDA) хорошей долгосрочной инвестицией в середине 2024 года?"
console.print ( f"--- 📈 Запуск инвестиционного комитета для: {query} ---" ) result = ensemble_agent.invoke({ "query" : query}) # ... (код для вывода отдельных отчетов и окончательной рекомендации CIO) ...
Эффективность этой архитектуры становится очевидной сразу же, как только вы видите результаты. Три аналитика дают совершенно разные отчеты: «Бычий» дает восторженную рекомендацию «Покупать», аналитик, ориентированный на стоимость, — осторожную «Держать», а количественный аналитик предоставляет нейтральные данные.
В итоговом отчете CIO не просто усредняют эти данные. В нем проводится настоящий синтез, признающий оптимистичный сценарий, но смягчающий его с учетом опасений относительно стоимости активов.
**Окончательная рекомендация:** Покупка
**Оценка уверенности:** 7,5 / 10
**Краткий обзор:**
Комитет представляет убедительные, но спорные аргументы в пользу NVIDIA. Единодушное мнение разделяет текущее технологическое превосходство компании ... Однако аналитики по стоимостному и количественному анализу поднимают важные, совпадающие вопросы о чрезвычайно высокой оценке акций... Окончательная рекомендация — «Покупка», но с сильным акцентом на долгосрочную позицию и рекомендацией осторожного входа...
**Выявленные возможности:**
* Бесспорное лидерство на рынке ускорителей ИИ.
* ...
**Выявленные риски:**
* Чрезвычайно высокая оценка (коэффициенты P/E и P/S).
* ...
Это гораздо более надежный и заслуживающий доверия ответ, чем тот, который мог бы дать любой отдельный агент. Для его формализации нашему эксперту-магистру права необходимо оценить глубину анализа и сбалансированность.
class EnsembleEvaluation (BaseModel):
analytical_depth_score: int = Field (description= "Оценка от 1 до 10 по глубине анализа." )
nuance_and_balance_score: int = Field (description= "Оценка от 1 до 10 по тому, насколько хорошо окончательный ответ сбалансировал противоречивые точки зрения и представил взвешенный вывод." )
justification: str = Field (description= "Краткое обоснование оценок." )
По результатам оценки, выступление ансамбля заслуживает высшей оценки.
--- Оценка результатов работы ансамблевого агента ---
{
'analytical_depth_score' : 9 ,
'nuance_and_balance_score' : 8 ,
'justification' : "Окончательный ответ исключительно сбалансирован. Он не просто выбирает сторону, а мастерски синтезирует оптимистичный сценарий роста со скептическими опасениями по поводу оценки, предоставляя тонкую рекомендацию, отражающую реальную сложность инвестиционного решения. Это высококачественный и надежный анализ."
}
Как видите, использование совокупности различных точек зрения повышает надежность и глубину рассуждений вашего агента, подобно тому, что мы наблюдали при использовании модели глубокого мышления.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 52
Эпизодическая + Семантическая память
Для всех наших агентов, у которых память как у золотой рыбки, но как только разговор заканчивается, все забывается.
Для создания по-настоящему персонализированного помощника, который учится и развивается вместе с пользователем, нам необходимо наделить его компонентом долговременной памяти.
Архитектура «Эпизодическая + Семантическая память» имитирует человеческое познание, предоставляя агенту два типа памяти:

Эпизодическая память (созданная
Фарид Хан
)
Эпизодическая память: это память о конкретных событиях, например, о прошлых разговорах. Она отвечает на вопрос: «Что произошло?» Для этого мы будем использовать векторную базу данных .
Семантическая память: это память о структурированных фактах и взаимосвязях, извлеченных из этих событий. Она отвечает на вопрос: «Что я знаю?» Для этого мы будем использовать графовую базу данных (Neo4j) .
Возможно, вы знаете, что это лежит в основе персонализации любой системы искусственного интеллекта. Именно так бот для электронной коммерции запоминает ваш стиль, репетитор — ваши слабые места, а личный помощник — ваши проекты и предпочтения на протяжении недель и месяцев.
Вот как это работает…
Взаимодействие: Агент ведет диалог с пользователем.
Извлечение информации из памяти: При поступлении нового запроса агент осуществляет поиск релевантного контекста как в своей эпизодической (векторной), так и в семантической (графовой) памяти.
Расширенная генерация: извлеченные воспоминания используются для создания персонализированного, контекстно-зависимого ответа.
Создание памяти: После взаимодействия агент, «создающий память», анализирует разговор, составляет краткое изложение (эпизодическая память) и извлекает факты (семантическая память).
Хранение в памяти: Новые данные сохраняются в соответствующих базах данных.
В основе этой системы лежит «Создатель воспоминаний» — агент, отвечающий за обработку разговоров и создание новых воспоминаний. У него две задачи: создать краткое резюме для векторного хранилища и извлечь структурированные факты для графа.
# Пидантические модели для извлечения знаний
class Node ( BaseModel ):
id : str ; type : str
class Relationship ( BaseModel ):
source: Node; target: Node; type : str
class KnowledgeGraph ( BaseModel ):
relationships: List [Relationship]
def create_memories ( user_input: str , assistant_output: str ):
conversation = f"User: {user_input} \nAssistant: {assistant_output} "
# Создание эпизодической памяти (суммирование)
console. print ( "--- Создание эпизодической памяти (резюме) ---" )
summary_prompt = ChatPromptTemplate.from_messages([
" system" , "Вы эксперт по составлению резюме. Создайте краткое резюме следующего взаимодействия пользователя и помощника в одно предложение. Это резюме будет использоваться в качестве памяти для последующего воспроизведения." ),
( "human" , "Взаимодействие:\n{interaction}" )
])
summarizer = summary_prompt | llm
episodic_summary = summarizer.invoke({ "interaction" : conversation}).content
new_doc = Document(page_content=episodic_summary, metadata={ "created_at" : uuid.uuid4(). hex })
episodic_vector_store.add_documents([new_doc])
console. print ( f"[green]Эпизодическая память создана:[/green] ' {episodic_summary} '" ) # Создание
семантической памяти (извлечение фактов)
console.print ( "--- Создание семантической памяти (графа) ---" ) extraction_llm = llm.with_structured_output(KnowledgeGraph) extraction_prompt = ChatPromptTemplate.from_messages([ " system" , "Вы эксперт по извлечению знаний. Ваша задача — определить ключевые сущности и их взаимосвязи из разговора и смоделировать их в виде графа. Сосредоточьтесь на предпочтениях пользователя, целях и заявленных фактах." ), ( "human" , "Извлечь все взаимосвязи из этого взаимодействия:\n{interaction}" ) ]) extractor = extraction_prompt | extraction_llm try
:
kg_data = extractor.invoke({ "interaction" : conversation})
if kg_data.relationships:
for rel in kg_data.relationships:
graph.add_graph_documents([rel], include_source= True )
console. print ( f"[green]Создана семантическая память:[/green]Добавлено { len (kg_data.relationships)} связей в граф." )
else :
console. print ( "[yellow]В этом взаимодействии не обнаружено новых семантических воспоминаний.[/yellow]" )
except Exception as e:
console. print ( f"[red]Не удалось извлечь или сохранить семантическую память: {e} [/red]" )
Имея готовый механизм формирования памяти, мы можем создать полноценный агент. Граф представляет собой простую последовательность: retrieveвоспоминания, generateответ с их использованием, а затем updateвоспоминание с новым диалогом.
class AgentState ( TypedDict ):
user_input: str
retrieved_memories: Optional [ str ]
generation: str
def retrieve_memory ( state: AgentState ) -> Dict [ str , Any ]:
"""Узел, который извлекает воспоминания как из эпизодической, так и из семантической памяти."""
console. print ( "--- Извлечение воспоминаний ---" )
user_input = state[ 'user_input' ]
# Извлечение из эпизодической памяти
retrieved_docs = episodic_vector_store.similarity_search(user_input, k= 2 )
episodic_memories = "\n" .join([doc.page_content for doc in retrieved_docs])
# Извлечение из семантической памяти
# Это простое извлечение; Более продвинутый вариант предполагает извлечение сущностей из запроса.
Попробуйте :
graph_schema = graph.get_schema
# Использование полнотекстового индекса для лучшего поиска. Neo4j автоматически создает его на основе свойств узлов.
# Более надежное решение может включать предварительное извлечение сущностей из user_input.
semantic_memories = str (graph.query( """
UNWIND $keywords AS keyword
CALL db.index.fulltext.queryNodes("entity", keyword) YIELD node, score
MATCH (node)-[r]-(related_node)
RETURN node, r, related_node LIMIT 5
""" , { 'keywords' : user_input.split()}))
except Exception as e:
semantic_memories = f"Не удалось выполнить запрос к графу: {e} "
retrieved_content = f"Релевантные прошлые разговоры (эпизодическая память):\n {episodic_memories} \n\nРелевантные факты (семантическая память):\n {semantic_memories} "
console. print ( f"[cyan]Retrieved Context:\n {retrieved_content} [/cyan]" )
return { "retrieved_memories" : retrieved_content}
def generate_response ( state: AgentState ) -> Dict [ str , Any ]:
"""Узел, генерирующий ответ с использованием полученных воспоминаний.
консоль. печать( "--- Генерация ответа ---" )
prompt = ChatPromptTemplate.from_messages([
( "system" , "Вы полезный и персонализированный финансовый помощник. Используйте полученные воспоминания, чтобы сформировать свой ответ и адаптировать его к пользователю. Если воспоминания указывают на предпочтения пользователя (например, он консервативный инвестор), вы ОБЯЗАТЕЛЬНО должны их уважать." ),
( "human" , "Мой вопрос: {user_input}\n\nВот несколько воспоминаний, которые могут быть актуальны:\n{retrieved_memories}" ) ]
)
generator = prompt | llm
generation = generator.invoke(state).content
console. print ( f"[green]Сгенерированный ответ:\n {generation} [/green]" )
return { "generation" : generation}
def update_memory ( state: AgentState ) -> Dict [ str , Any ]:
"""Узел, который обновляет память последним взаимодействием."""
console. print ( "--- Обновление памяти ---" )
create_memories(state[ 'user_input' ], state[ 'generation' ])
return {}
workflow = StateGraph(AgentState)
workflow.add_node( "retrieve" , retrieve_memory)
workflow.add_node( "generate" , generate_response)
workflow.add_node( "update" , update_memory)
# ... (последовательное подключение узлов) ...
memory_agent = workflow.compile ( )

Эпизодическая память (созданная
Фарид Хан
)
Единственный способ это проверить — провести многоходовый диалог. Один диалог будет посвящен заполнению памяти, а второй — проверке способности агента её использовать.
# Взаимодействие 1: Заполнение памяти
run_interaction( "Привет, меня зовут Алекс. Я консервативный инвестор, в основном интересуюсь состоявшимися технологическими компаниями." )
# Взаимодействие 2: ТЕСТ ПАМЯТИ
run_interaction( "Исходя из моих целей, какая хорошая альтернатива Apple?" )
--- 💬 ВЗАИМОДЕЙСТВИЕ 1: Заполнение памяти ---
--- Извлечение воспоминаний...
Извлеченный контекст: Прошлые разговоры + исходный документ...
--- Генерация ответа...
Сгенерированный ответ: Привет, Алекс! Стратегия консервативного инвестора учтена...
--- Обновление памяти...
Создана эпизодическая память: «Пользователь Алекс — консервативный инвестор в сфере технологий...»
Создана семантическая память: Добавлено 2 связи...
--- 💬 ВЗАИМОДЕЙСТВИЕ 2: Задавание конкретного вопроса ---
--- Извлечение воспоминаний...
Извлеченный контекст: Алекс как консервативный инвестор...
--- Генерация ответа...
Сгенерированный ответ: Apple (AAPL) подходит для консервативного технологического портфеля, сильный бренд, стабильный доход...
--- Обновление памяти...
Создана эпизодическая память: «Пользователь спросил об Apple; помощник подтвердил соответствие...»
Создана семантическая память: Добавлено 1 связь...
Агент без сохранения состояния не справляется со вторым запросом, потому что не знает целей Алекса. Наш же агент с расширенной памятью успешно выполняет запрос.
Функция «Эпизодоичное воспроизведение» извлекает краткое содержание первого разговора: «Пользователь, Алекс, представился как консервативный инвестор…»
Напомним, что семантический подход заключается в следующем: он запрашивает информацию из графа и находит следующий факт: (User: Alex) -[HAS_GOAL]-> (InvestmentPhilosophy: Conservative).
Синтез: Используя этот объединенный контекст, система дает идеальную, персонализированную рекомендацию.
Мы можем формализовать это с помощью магистра права в качестве судьи, который будет оценивать персонализацию.
class PersonalizationEvaluation ( BaseModel ):
personalization_score: int = Field(description= "Оценка от 1 до 10 того, насколько хорошо агент использовал прошлые взаимодействия и предпочтения пользователя для адаптации своего ответа." )
justification: str = Field(description= "Краткое обоснование оценки." )
По результатам оценки, агент получает высший балл.
--- Оценка персонализации ответа агента памяти ---
{
'personalization_score': 7,
'justification': "Ответ агента был идеально персонализирован. Он явно ссылался на заявленную цель пользователя — быть 'консервативным инвестором' (что он вспомнил из предыдущего разговора), — чтобы обосновать свою рекомендацию Microsoft. Это демонстрирует глубокое, осознанное понимание пользователя."
}
Путем сочетания эпизодической и семантической памяти…
Мы можем создавать агентов, которые выходят за рамки простых вопросов и ответов и становятся настоящими помощниками в обучении.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 46
Доска
Если проблема всегда одна и та же, то предыдущие архитектуры могли бы сработать…
Но что, если лучший следующий шаг зависит от результатов предыдущего? Жесткая последовательность может быть невероятно неэффективной, заставляя систему выполнять ненужные шаги.
Вот тут-то и пригодится архитектура Blackboard . Это более продвинутый и гибкий способ координации работы команды специалистов. Идея основана на том, как эксперты решают проблемы.
Они собираются вокруг доски, общего рабочего пространства, где каждый может записать свои наблюдения.
Затем руководитель просматривает доску объявлений и решает, кто должен внести свой вклад следующим.
При разработке архитектуры Blackboard — это шаблон для решения сложных, плохо структурированных задач, где путь к решению заранее неизвестен. Он позволяет применять спонтанную, оппортунистическую стратегию, что делает его идеальным для динамического осмысления ситуации или сложной диагностики, где следующий шаг всегда является реакцией на последнее открытие.
Давайте разберемся в этом процессе...
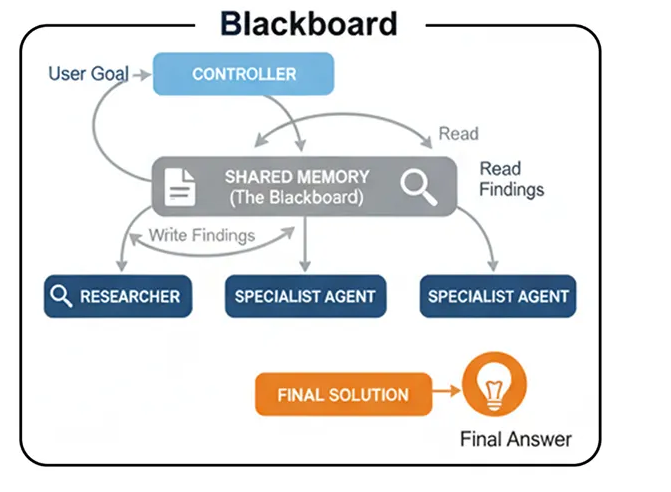
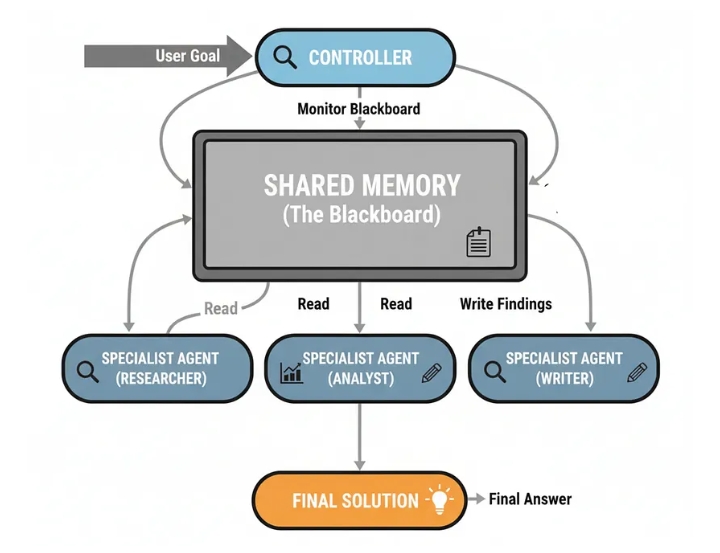
Память Blackboard (создано пользователем)
Фарид Хан
)
Разделяемая память (как в «Доске объявлений»): центральное хранилище данных содержит текущее состояние проблемы и все полученные на данный момент результаты.
Специалисты-агенты: Группа независимых агентов, каждый из которых обладает определенными навыками, следит за доской объявлений.
Контроллер: Центральный агент-«контроллер» также следит за доской. Его задача — анализировать текущее состояние и решать, какой специалист лучше всего подготовлен к следующему шагу.
Оппортунистическая активация: Контроллер активирует выбранного агента. Агент считывает данные с доски, выполняет свою работу и записывает результаты обратно.
Итерация: Этот процесс повторяется, при этом контроллер динамически выбирает следующего агента, пока не решит, что проблема решена.
Давайте начнём его строить.
Наиболее важной частью этой системы является интеллектуальный контроллер . В отличие от нашего предыдущего мета-контроллера, который выполнял только однократную отправку команды, этот работает в цикле. После выполнения каждой команды специалистом контроллер повторно оценивает доску объявлений и решает, что делать дальше.
class BlackboardState ( TypedDict ):
user_request: str
blackboard: List [ str ] # Общее рабочее пространство
available_agents: List [ str ]
next_agent: Optional [ str ] # Решение контроллера
class ControllerDecision ( BaseModel ):
next_agent: str = Field(description= "Имя следующего вызываемого агента. Должно быть одним из ['News Analyst', 'Technical Analyst', 'Financial Analyst', 'Report Writer'] или 'FINISH'." )
reasoning: str = Field(description= "Краткое обоснование выбора следующего агента." )
def controller_node ( state: BlackboardState ):
"""Интеллектуальный контроллер, который анализирует доску и принимает решение о следующем шаге."""
console. print ( "--- КОНТРОЛЛЕР: Анализ доски... ---" )
controller_llm = llm.with_structured_output(ControllerDecision)
blackboard_content = "\n\n" .join(state[ 'blackboard' ])
prompt = f"""Вы являетесь центральным контроллером многоагентной системы. Ваша задача — проанализировать общую доску и исходный запрос пользователя, чтобы решить, какой специализированный агент должен запуститься следующим.
**Исходный запрос пользователя:**
{state[ 'user_request' ]}
**Текущее содержимое доски:**
---
{blackboard_content if blackboard_content else "Доска в данный момент пуста." }
---
**Доступные специализированные агенты:**
{ ', ' .join(state[ 'available_agents' ])}
**Ваша задача:**
1. Внимательно прочтите запрос пользователя и текущее содержимое доски.
2. Определите, какой *следующий логический шаг* необходимо предпринять, чтобы приблизиться к полный ответ.
3. Выберите единственного наиболее подходящего агента для выполнения этого шага.
4. Если запрос был полностью обработан, выберите «ЗАВЕРШИТЬ».
Предоставьте свое решение в требуемом формате.
"""
decision = controller_llm.invoke(prompt)
console. print ( f"--- КОНТРОЛЛЕР: Решение состоит в вызове ' {decision.next_agent} '. Причина:{decision.reasoning} ---" )
return {"next_agent" : decision.next_agent}
Теперь нам осталось только подключить это в LangGraph. Ключевым моментом является центральный цикл: любой специализированный агент после выполнения задания отправляет управление обратно для принятия Controllerследующего решения.
# ... (специализированные узлы определяются аналогично многоагентной системе) ...
bb_graph_builder = StateGraph(BlackboardState)
bb_graph_builder.add_node( "Controller" , controller_node)
bb_graph_builder.add_node( "News Analyst" , news_analyst_bb)
# ... добавить другие специализированные узлы ...
bb_graph_builder.set_entry_point( "Controller" )
def route_to_agent ( state: BlackboardState ):
return state[ "next_agent" ]
bb_graph_builder.add_conditional_edges( "Controller" , route_to_agent, {
"News Analyst" : "News Analyst" ,
# ... другие маршруты ...
"FINISH" : END
})
# После выполнения любого специализированного узла управление всегда возвращается к Controller
bb_graph_builder.add_edge( "News Аналитик" , "Контроллер" )
# ... другие ребра обратно к контроллеру ...
blackboard_app = bb_graph_builder.compile ( )
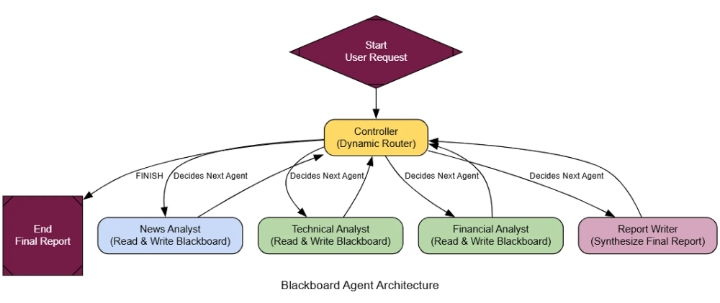
Архитектура Blackboard (создано компанией...)
Фарид Хан
)
Чтобы понять, почему это намного лучше, чем жесткая последовательность, давайте дадим ему задачу с условной логикой, в которой последовательный агент потерпит неудачу.
dynamic_query = "Найти последние важные новости о Nvidia. В зависимости от настроения новости провести либо технический анализ (если новость нейтральная или позитивная), либо финансовый анализ (если новость негативная)."
initial_bb_input = { "user_request" : dynamic_query, "blackboard" : [], "available_agents" : [ "News Analyst" , "Technical Analyst" , "Financial Analyst" , " Report Writer " ] }
final_bb_output = blackboard_app.invoke(initial_bb_input, { "recursion_limit" : 10 })
console. print ( "\n--- [bold green]Итоговый отчет из системы Blackboard[/bold green] ---" )
console. print (Markdown(final_bb_output[ 'blackboard' ][- 1 ]))
--- КОНТРОЛЛЕР: Анализ доски... ---
Решение: вызвать «Аналитика новостей»...
--- Состояние доски ---
АГЕНТ «Аналитик новостей» работает...
--- КОНТРОЛЛЕР: Анализ доски... ---
Решение: вызвать «Технического аналитика» (новости позитивные)...
--- Состояние доски ---
Отчет 1: Позитивные новости о Nvidia, новый чип с ИИ «Rubin», бычий настрой рынка...
--- (Доска) АГЕНТ «Технический аналитик» работает... ---
--- КОНТРОЛЛЕР: Анализ доски... ---
Решение: вызвать «Автора отчета» (анализ завершен, подготовить отчет)...
...
Трассировка выполнения показывает гораздо более интеллектуальный процесс. Последовательный агент запустил бы одновременно технический и финансовый анализ, что привело бы к нерациональному расходованию ресурсов. Наша система Blackboard умнее:
Запуск контроллера: Он видит пустую плату и вызывает News Analyst.
Программа News Analyst Runs: находит позитивные новости о Nvidia и публикует их на форуме.
Контролер пересматривает ситуацию: он читает позитивные новости и правильно решает, что следующим шагом будет звонок в службу поддержки Technical Analyst, полностью пропуская финансовый вопрос.
Выполнение задачи специалистом: технический аналитик выполняет свою работу и публикует отчет.
Контроллер завершает работу: он видит, что весь необходимый анализ выполнен, и вызывает функцию Report Writerдля синтеза окончательного ответа перед завершением.
Этот динамичный, основанный на оперативности рабочий процесс — именно то, что определяет систему Blackboard . Для большей формальности наш магистр права, выступающий в роли судьи, оценивает каждый вклад, выставляя баллы за логическую согласованность и эффективность , гарантируя, что предлагаемые решения являются одновременно обоснованными и применимыми на практике.
class ProcessLogicEvaluation ( BaseModel ):
instruction_following_score: int = Field(description= "Оценка от 1 до 10 того, насколько хорошо агент следовал условным инструкциям." )
process_efficiency_score: int = Field(description= "Оценка от 1 до 10 того, избегал ли агент ненужной работы." )
justification: str = Field(description= "Краткое обоснование оценок." )
Последовательный агент получил бы здесь ужасные результаты. Однако наша система Blackboard справляется с тестом на отлично.
--- Оценка процесса работы системы Blackboard ---
{
'instruction_following_score': 7,
'process_efficiency_score': 8,
'justification': "Агент идеально следовал условным инструкциям пользователя. После того, как аналитик новостей сообщил о позитивном настроении, система правильно выбрала запуск технического аналитика и полностью пропустила финансового аналитика. Это демонстрирует как безупречное следование инструкциям, так и оптимальную эффективность процесса."
}
В сложных задачах, где дальнейший путь зависит от промежуточных результатов, гибкость…
Архитектура Blackboard может быть лучше, чем многоагентная система.
Страница 2 из 4
- Вы здесь:
-
Главная

- Шаблоны мультиагентных систем