
Цикл самосовершенствования (аналогия RLHF)
Агент, которого мы создаём сегодня, останется тем же самым агентом и завтра.
Для создания системы, которая действительно учится и совершенствуется со временем, нам необходим цикл самосовершенствования .
Эта архитектура имитирует цикл обучения человека do -> get feedback -> improve. Мы создадим рабочий процесс, в котором результаты работы агента будут немедленно оценены, и если они окажутся недостаточно хорошими, агент будет вынужден пересмотреть свою работу на основе конкретной обратной связи.
Это ключ к достижению экспертного уровня производительности в любой системе распознавания/обучения агентов. Именно так вы обучаете агента, чтобы он перешел от неплохого базового уровня к первоклассному исполнителю. Сохраняя лучшие, проверенные результаты, вы создаете «золотой стандарт» данных, который служит основой для всей будущей работы, формируя систему, которая учится на своих успехах.
Простой процесс RLHF для агентов работает следующим образом…
Нажмите Enter или щелкните, чтобы просмотреть изображение в полном размере.
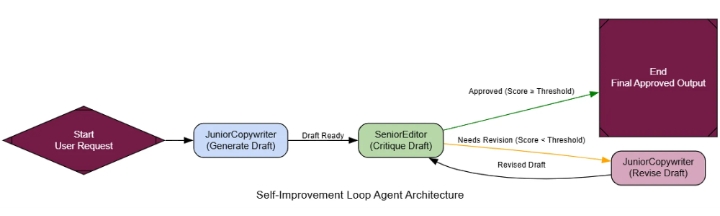
Процесс RLHF
Создание первоначального результата: «младший» агент создает первый черновик.
Результат критики: Опытный критик оценивает черновик по строгой системе критериев.
Решение: Система проверяет, соответствует ли оценка рецензии пороговому значению качества.
Пересмотр (цикл): Если оценка слишком низкая, первоначальный вариант и отзывы критика передаются обратно младшему агенту для создания пересмотренной версии.
Принятие: После подтверждения вывода цикл завершается.
Мы создадим JuniorCopywriterагента для генерации маркетинговых писем и SeniorEditorагента для их анализа. Ключевым моментом является структурированный результат анализа, предоставляющий полезную обратную связь.
class MarketingEmail ( BaseModel ):
"""Представляет собой черновик маркетингового письма."""
subject: str = Field(description= "Запоминающаяся и лаконичная тема письма." )
body: str = Field(description= "Полный текст письма, написанный в формате Markdown." )
class Critique ( BaseModel ):
"""Структурированная критика черновика маркетингового письма."""
score: int = Field(description= "Общая оценка качества от 1 (плохо) до 10 (отлично)." )
feedback_points: List [ str ] = Field(description= "Маркированный список конкретных, действенных пунктов обратной связи для улучшения." )
is_approved: bool = Field(description= "Логическое значение, указывающее, одобрен ли черновик (оценка >= 8). Это дублирует оценку, но полезно для маршрутизации." )
# --- 1. Генератор: Младший копирайтер ---
def get_generator_chain ():
prompt = ChatPromptTemplate.from_messages([
( "system" , "Вы — начинающий копирайтер в сфере маркетинга. Ваша задача — написать первый черновик маркетингового письма на основе запроса пользователя. Проявите креативность, но сосредоточьтесь на донесении основной мысли." ),
( "human" , "Напишите маркетинговое письмо на следующую тему:\n\n{request}" ) ]
)
return prompt | llm.with_structured_output(MarketingEmail)
# --- 2. Критик: Старший редактор ---
def get_critic_chain ():
prompt = ChatPromptTemplate.from_messages([
( "system" , """Вы — старший редактор по маркетингу и бренд-менеджер. Ваша задача — оценить черновик электронного письма, написанный младшим копирайтером.
Оцените черновик по следующим критериям:
1. **Запоминающаяся тема:** Является ли тема письма привлекательной и вероятно ли, что оно будет открыто?
2. **Ясность и убедительность:** Является ли основной текст ясным, убедительным и убедительным?
3. **Сильный призыв к действию (CTA):** Есть ли четкое, единственное действие, которое должен совершить пользователь?
4. **Тон бренда:** Является ли тон профессиональным, но в то же время доступным?
Присвойте оценку от 1 до 10. Оценка 8 или выше означает, что черновик одобрен для отправки. Предоставьте конкретные,
"Полезная обратная связь, которая поможет автору улучшить свои навыки."" ),
("человек" , "Пожалуйста, оцените следующий черновик электронного письма:\n\n**Тема:** {тема}\n\n**Текст:**\n{текст}" )
])
return prompt | llm.with_structured_output(Critique)
# --- 3. Редактор (Генератор в режиме «Редактировать») ---
def get_reviser_chain ():
prompt = ChatPromptTemplate.from_messages([
( "system" , "Вы — младший копирайтер, написавший первоначальный черновик. Вы только что получили отзыв от старшего редактора. Ваша задача — тщательно отредактировать черновик, чтобы учесть каждый пункт отзыва. Создайте новую, улучшенную версию письма." ),
( "human" , "Первоначальный запрос: {request}\n\nВот ваш первоначальный черновик:\n**Тема:** {original_subject}\n**Текст:**\n{original_body}\n\nВот отзыв от вашего редактора:\n{feedback}\n\nПожалуйста, предоставьте отредактированное письмо." )
])
return prompt | llm.with_structured_output(MarketingEmail)
Теперь нам нужно просто подключить это в LangGraph с помощью условного ребра, которое проверяет is_approvedфлаг из критической оценки. Если он равен False, мы возвращаемся к revise_node.
# ... (определение состояния) ...
def should_continue ( state: AgentState ) -> str :
"""Проверяет критику, чтобы решить, зацикливаться или завершать."""
if state[ 'critique' ].is_approved:
return "end"
if state[ 'revision_number' ] >= 3 : # Максимальный лимит ревизий
return "end"
else :
return "continue"
workflow = StateGraph(AgentState)
workflow.add_node( "generate" , generate_node)
workflow.add_node( "critique" , critique_node)
workflow.add_node( "revise" , revise_node)
workflow.set_entry_point( "generate" )
workflow.add_edge( "generate" , "critique" )
workflow.add_conditional_edges( "critique" , should_continue, { "continue" : "revise" , " end" : END})
workflow.add_edge( "revise" , "critique" )
self_refine_agent = workflow.compile ()
RlHF
Давайте дадим ему задание и посмотрим, как оно будет учиться.
request = "Написать маркетинговое письмо для нашей новой платформы обработки данных на основе ИИ, 'InsightSphere'."
final_result = run_agent(request) # Предполагается, что run_agent передает процесс в потоковом режиме
На графике выходных данных показано, как агент обучается в режиме реального времени.
--- Шаг: Создание ---
Черновик 1
Тема: Анонс нового продукта
Текст: Мы рады объявить о нашем новом продукте, InsightSphere... ---
Шаг: Критика (Редакция №1) ---
Оценка результата критики
: 4/10 Отзыв: - Тема слишком общая . - Текст слишком упрощенный ... - Призыв к действию слабый . --- Шаг: Редактирование --- Черновик 2 Тема: Раскройте истинный потенциал ваших данных с помощью InsightSphere Текст: Вам сложно превратить огромные массивы данных в полезные аналитические выводы? Мы рады представить **InsightSphere**... --- Шаг: Критика (Редакция №2) --- Оценка результата критики : 9/10 Отзыв: - Отличная работа над редакцией. Одобрено .
Агент взял ужасный первый черновик и, руководствуясь замечаниями редактора, превратил его в высококачественный маркетинговый текст.
Для формализации этого процесса нашему магистру права, выступающему в роли судьи, необходимо оценивать качество работы.
class QualityImprovementEvaluation ( BaseModel ):
initial_quality_score: int = Field(description= "Оценка от 1 до 10 качества первоначального варианта." )
final_quality_score: int = Field(description= "Оценка от 1 до 10 качества окончательного, переработанного варианта." )
justification: str = Field(description= "Краткое обоснование оценок с указанием улучшений." )
При оценке улучшения очевидны.
--- Оценка процесса самосовершенствования ---
{
'initial_quality_score': 3,
'final_quality_score': 9,
'justification': "Агент продемонстрировал значительное улучшение. Первоначальный черновик был общим и неэффективным. Окончательная версия, после учета критики, оказалась убедительной, хорошо структурированной и содержала сильный призыв к действию. Цикл самосовершенствования был весьма успешным."
}
Хотя показатель качества не очень высок, в нашем процессе четко прослеживается следующее…
Благодаря этому циклу самообучения мы можем улучшить результаты работы агента, переведя их из удовлетворительного состояния в отличное , и с каждым раундом добиваться лучших результатов.