
Шаблоны мультиагентных систем
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 74
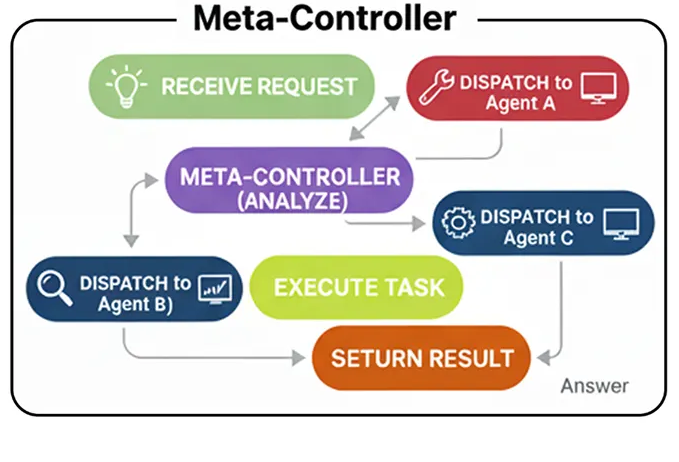
Мета-контроллер
В многоагентной команде вы, возможно, заметили некоторую жесткость. Мы жестко задали последовательность: News -> Technical -> Financial -> Writer.
А что, если пользователю нужен только технический анализ? Наша система все равно будет тратить время и деньги на запуск других аналитических инструментов.
В архитектуре Meta-Controller используется интеллектуальный диспетчер. Единственная задача этого агента-контроллера — проанализировать запрос пользователя и определить, какой специалист лучше всего подходит для выполнения этой задачи.
В системах RAG или агентных системах Мета-контроллер является центральной нервной системой. Это своего рода «входная дверь», которая направляет входящие запросы в нужный отдел.
Простейшая версия контроллера Meta работает следующим образом:

Инструмент, использующий рабочий процесс (создан пользователем)
Фарид Хан
)
Получение запроса: Агент получает запрос от пользователя.
Решение: Агент анализирует запрос и рассматривает доступные инструменты. Затем он решает, необходим ли тот или иной инструмент для точного ответа на вопрос.
Действие: Если требуется инструмент, агент формирует вызов этого инструмента, например, конкретной функции с правильными аргументами.
Наблюдение: Система выполняет вызов инструмента, и результат («наблюдение») отправляется обратно агенту.
Синтез: Агент берет выходные данные инструмента, объединяет их со своими собственными рассуждениями и генерирует окончательный, обоснованный ответ для пользователя.
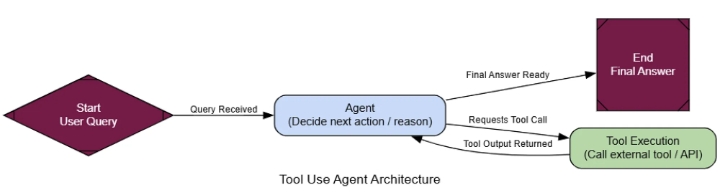
Для этого нам нужно предоставить нашему агенту инструмент. Для этого мы будем использовать TavilySearchResultsинструмент, который дает нашему агенту доступ к поиску в интернете. Самая важная часть здесь — описание . LLM читает это описание на естественном языке, чтобы понять, что делает инструмент и когда его следует использовать, поэтому сделать его ясным и точным — ключ к успеху.
# Инициализируем инструмент. Мы можем установить максимальное количество результатов, чтобы контекст был кратким.
search_tool = TavilySearchResults(max_results= 2 )
# Крайне важно дать инструменту четкое имя и описание для агента.
search_tool.name = "web_search"
search_tool.description = "Инструмент, который можно использовать для поиска в интернете актуальной информации по любой теме, включая новости, события и текущие события."
tools = [search_tool]
Теперь, когда у нас есть функциональный инструмент, мы можем создать агента, который научится им пользоваться. Состояние агента, использующего инструмент, довольно простое: это всего лишь список сообщений, отслеживающий всю историю разговора.
class AgentState ( TypedDict ):
messages: Annotated[ list [AnyMessage], add_messages]
Далее нам необходимо сообщить LLM о предоставленных нам инструментах. Это критически важный шаг. Мы используем .bind_tools()метод, который, по сути, внедряет название и описание инструмента в системную подсказку LLM, позволяя ему самому решать, когда вызывать этот инструмент.
llm = ChatNebius(model= "meta-llama/Meta-Llama-3.1-8B-Instruct" , temperature= 0 )
# Привязываем инструменты к LLM, делая его совместимым с инструментами
llm_with_tools = llm.bind_tools(tools)
Теперь мы можем определить рабочий процесс нашего агента с помощью LangGraph. Нам нужны два основных узла: agent_node«мозг», который вызывает LLM для принятия решения о дальнейших действиях, и tool_node«руки», которые фактически выполняют инструмент.
def agent_node ( state: AgentState ):
"""Первичный узел, который вызывает LLM для принятия решения о следующем действии."""
console. print ( "--- АГЕНТ: Размышляет... ---" )
response = llm_with_tools.invoke(state[ "messages" ])
return { "messages" : [response]}
# ToolNode — это предварительно созданный узел из LangGraph, который выполняет инструменты
tool_node = ToolNode(tools)
После agent_nodeвыполнения заданий нам нужен маршрутизатор, чтобы определить, куда двигаться дальше. Если последнее сообщение агента содержит tool_callsатрибут, это означает, что он хочет использовать инструмент, поэтому мы направляем его к этому инструменту tool_node. В противном случае это означает, что у агента есть окончательный ответ, и мы можем завершить рабочий процесс.
def router_function ( state: AgentState ) -> str :
"""Проверяет последнее сообщение агента, чтобы решить, какой будет следующий шаг."""
last_message = state[ "messages" ][- 1 ]
if last_message.tool_calls:
# Агент запросил вызов инструмента
console. print ( "--- МАРШРУТИЗАТОР: Решение — вызвать инструмент. ---" )
return "call_tool"
else :
# Агент предоставил окончательный ответ
console. print ( "--- МАРШРУТИЗАТОР: Решение — завершить. ---" )
return "__end__"
Хорошо, у нас есть все необходимые элементы. Давайте соединим их в граф. Ключевым моментом здесь является условное ребро, которое использует наш механизм router_functionдля создания основного цикла рассуждений агента: agent-> router-> tool-> agent.
graph_builder = StateGraph(AgentState)
# Добавить узлы
graph_builder.add_node( "agent" , agent_node)
graph_builder.add_node( "call_tool" , tool_node)
# Установить точку входа
graph_builder.set_entry_point( "agent" )
# Добавить условный маршрутизатор
graph_builder.add_conditional_edges(
"agent" ,
router_function,
)
# Добавить ребро от узла инструмента обратно к агенту, чтобы завершить цикл
graph_builder.add_edge( "call_tool" , "agent" )
# Скомпилировать граф
tool_agent_app = graph_builder. compile ()
Мета-контроллер (создан пользователем)
Фарид Хан
)
Теперь давайте протестируем наш диспетчер с помощью различных подсказок. Каждая из них предназначена для проверки того, отправляет ли диспетчер запрос нужному специалисту.
# Тест 1: Следует перенаправить на специалиста широкого профиля
run_agent( "Здравствуйте, как дела сегодня?" )
# Тест 2: Следует перенаправить на исследователя
run_agent( "Какие были последние финансовые результаты NVIDIA?" )
# Тест 3: Следует перенаправить на программиста
run_agent( "Можете ли вы написать мне функцию на Python для вычисления n-го числа Фибоначчи?" )
На графике выходных данных видно, что контроллер каждый раз принимает взвешенные решения.
--- 🧠 Мета-контроллер анализирует запрос ---
[жёлтый]Решение о маршрутизации:[/жёлтый] Отправить [жирный]Специалисту[/жирный]. [курсив]Причина: Запрос пользователя — простое приветствие...[/курсив]
Окончательный ответ: Здравствуйте! Чем я могу вам сегодня помочь?
--- 🧠 Мета-контроллер анализирует запрос ---
[жёлтый]Решение о маршрутизации:[/жёлтый] Отправить [жирный]Исследователю[/жирный]. [курсив]Причина: Пользователь спрашивает о недавнем событии...[/курсив]
Окончательный ответ: Последние финансовые результаты NVIDIA... были исключительно сильными. Они сообщили о выручке в размере 26,04 миллиарда долларов...
--- 🧠 Мета-контроллер анализирует запрос ---
[жёлтый]Решение о маршрутизации:[/жёлтый] Отправить [жирный]Программисту[/жирный]. [курсив]Причина: Пользователь явно запрашивает функцию Python...[/курсив]
Окончательный ответ:
```python
def fibonacci(n):
# ... (код) ...
``` {data-source-line="130"}
Система работает безупречно. Приветствие отправляется специалисту широкого профиля, запрос новостей — исследователю, а запрос кода — программисту. Контроллер корректно распределяет задачи в зависимости от их содержания.
Для формализации этого вопроса мы будем использовать LLM в качестве судьи, который оценивает только один параметр: корректность маршрутизации.
class RoutingEvaluation ( BaseModel ):
"""Схема для оценки решения метаконтроллера о маршрутизации.""
routing_correctness_score: int = Field(description= "Оценка от 1 до 10, показывающая, выбрал ли контроллер наиболее подходящего специалиста для запроса." )
justification: str = Field(description= "Краткое обоснование оценки." )
На вопрос типа «Какова столица Франции?» оценка судьи будет следующей:
--- Оценка маршрутизации метаконтроллера ---
{
'routing_correctness_score': 8.5,
'justification': "Контроллер правильно определил запрос пользователя как фактический запрос, требующий актуальной информации, и направил его агенту 'Исследователь'. Это был оптимальный выбор, поскольку у специалиста широкого профиля могли быть устаревшие знания."
}
Этот результат показывает, что наш контроллер не просто прокладывает маршруты, а грамотно распределяет задачи.
Это делает системы искусственного интеллекта масштабируемыми и простыми в обслуживании, поскольку новые навыки можно добавлять, подключая специалистов и обновляя контроллер.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 49
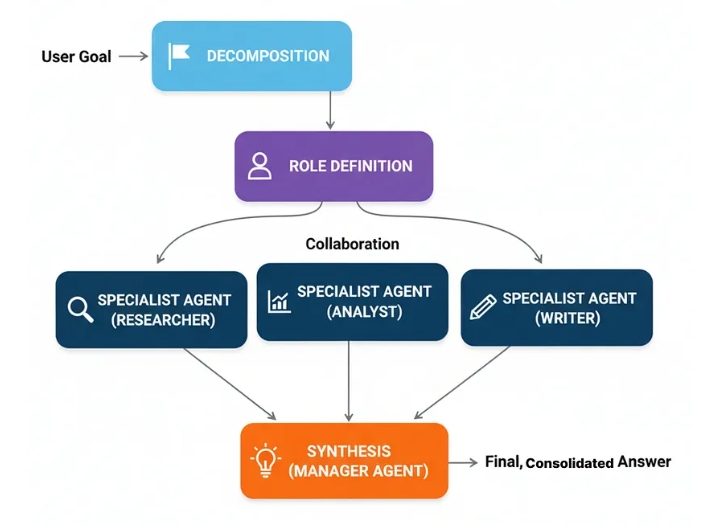
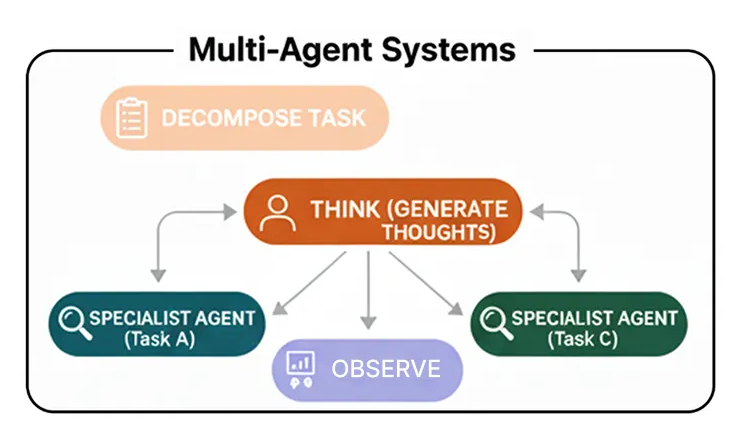
Многоагентные системы
Все подходы, которые мы применяли до сих пор, оказались эффективными сами по себе.
Что происходит, когда проблема слишком масштабна или слишком сложна, чтобы один агент мог эффективно её решить?
Вместо создания одного супер-агента, который делает всё, многоагентные системы используют команду специалистов. Каждый агент специализируется на своей области, подобно тому, как это делают эксперты-люди — вы же не попросите специалиста по анализу данных написать маркетинговый текст.
Для решения сложных задач, таких как составление анализа рынка, можно привлечь к совместной работе эксперта по новостям, финансового эксперта и эксперта по фондовому рынку для достижения лучшего результата.
Многоагентные системы могут быть очень сложными в плане реализации, но их упрощенная версия работает следующим образом…
Multi-Agent (Created by
Fareed Khan
)
Decomposition: A complex task is broken down into sub-tasks.
Role Definition: Each sub-task is assigned to a specialist agent based on its defined role (e.g., ‘Researcher’, ‘Coder’, ‘Writer’).
Collaboration: The agents execute their tasks, passing their findings to each other or a central manager.
Synthesis: A final ‘manager’ agent collects the outputs from the specialists and assembles the final, consolidated response.
To really see why a team is better, we first need a baseline. We will build a single, monolithic ‘generalist’ agent and give it a complex, multi-faceted task.
Then, we will build our specialist team: a News Analyst, a Technical Analyst, and a Financial Analyst. Each will be its own agent node with a very specific persona. A final Report Writer will act as the manager, compiling their work.
class AgentState(TypedDict):
user_request: str
news_report: Optional[str]
technical_report: Optional[str]
financial_report: Optional[str]
final_report: Optional[str]
# A helper factory to create our specialist nodes cleanly
def create_specialist_node(persona: str, output_key: str):
"""Factory function to create a specialist agent node."""
system_prompt = persona + "\n\nYou have access to a web search tool. Your output MUST be a concise report section, focusing only on your area of expertise."
prompt = ChatPromptTemplate.from_messages([("system", system_prompt), ("human", "{user_request}")])
agent = prompt | llm.bind_tools([search_tool])
def specialist_node(state: AgentState):
console.print(f"--- CALLING {output_key.replace('_report','').upper()} ANALYST ---")
result = agent.invoke({"user_request": state["user_request"]})
return {output_key: result.content}
return specialist_node
# Create the specialist nodes
news_analyst_node = create_specialist_node("You are an expert News Analyst...", "news_report")
technical_analyst_node = create_specialist_node("You are an expert Technical Analyst...", "technical_report")
financial_analyst_node = create_specialist_node("You are an expert Financial Analyst...", "financial_report")
def report_writer_node(state: AgentState):
"""The manager agent that synthesizes the specialist reports."""
console.print("--- CALLING REPORT WRITER ---")
prompt = f"""You are an expert financial editor. Your task is to combine the following specialist reports into a single, professional, and cohesive market analysis report.
News Report: {state['news_report']}
Technical Report: {state['technical_report']}
Financial Report: {state['financial_report']}
"""
final_report = llm.invoke(prompt).content
return {"final_report": final_report}
Now let’s wire them up in LangGraph. For this example, we’ll use a simple sequential workflow: the News Analyst goes first, then the Technical Analyst, and so on.
multi_agent_graph_builder = StateGraph(AgentState)
# Add all the nodes
multi_agent_graph_builder.add_node("news_analyst", news_analyst_node)
multi_agent_graph_builder.add_node("technical_analyst", technical_analyst_node)
multi_agent_graph_builder.add_node("financial_analyst", financial_analyst_node)
multi_agent_graph_builder.add_node("report_writer", report_writer_node)
# Define the workflow sequence
multi_agent_graph_builder.set_entry_point("news_analyst")
multi_agent_graph_builder.add_edge("news_analyst", "technical_analyst")
multi_agent_graph_builder.add_edge("technical_analyst", "financial_analyst")
multi_agent_graph_builder.add_edge("financial_analyst", "report_writer")
multi_agent_graph_builder.add_edge("report_writer", END)
multi_agent_app = multi_agent_graph_builder.compile()
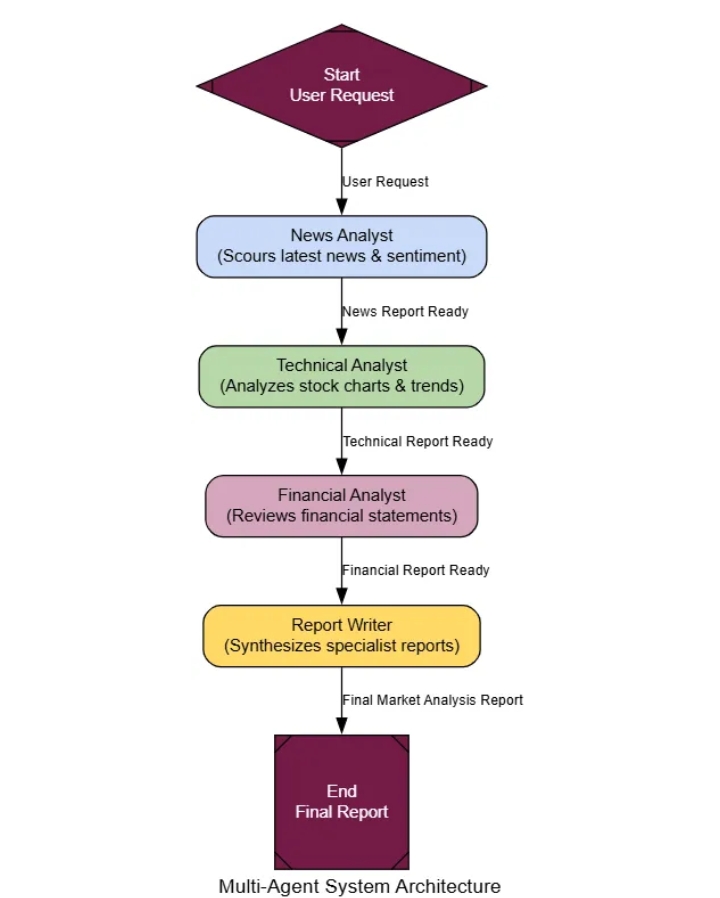
Многоагентная система (создана)
Давайте дадим нашей команде специалистов сложную задачу: создать полный аналитический отчет по рынку для NVIDIA. Один специалист широкого профиля, скорее всего, напишет поверхностный, неструктурированный текст. Посмотрим, как справится наша команда.
multi_agent_query = "Создать краткий, но исчерпывающий отчет об анализе рынка для NVIDIA (NVDA)."
console.print ( f "[bold green]Тестирование многоагентной команды на одной и той же задаче:[/bold green]\n' {multi_agent_query} '\n" )
final_multi_agent_output = multi_agent_app.invoke({ "user_request" : multi_agent_query})
console.print ( " \n--- [bold green]Итоговый отчет от многоагентной команды[/bold green] ---" )
console.print ( Markdown (final_multi_agent_output[ 'final_report' ]))
Разница в итоговом отчете существенна. Результаты работы многоагентной группы имеют четкую структуру, с ясными, отдельными разделами для каждой области анализа. Каждый раздел содержит более подробную, специфичную для данной области терминологию и выводы.
### Аналитический отчет по рынку: NVIDIA
**Введение**
NVIDIA вызывает большой интерес у инвесторов... В этом отчете объединены выводы трех специалистов...
**Отчет о новостях и настроениях**
Последние новости о NVIDIA были неоднозначными... Компания столкнулась с усилением конкуренции... но также добилась значительных успехов в области искусственного интеллекта...
**Отчет о техническом анализе**
Акции NVIDIA торговались в бычьем тренде в течение последнего года... В отчете также отмечается сильный рост прибыли компании...
**Отчет о финансовых показателях**
В отчете отмечается сильный рост выручки компании... Валовая маржа увеличивается...
**Заключение**
В заключение, анализ рынка NVIDIA показывает, что компания столкнулась с усилением конкуренции... но остается сильным игроком...
Результат намного превосходит то, что мог бы получить один человек. Разделив работу, мы получаем структурированный, глубокий и профессиональный результат.
Для формализации этого процесса мы будем использовать магистра права в качестве судьи, который будет оценивать качество итогового отчета.
class ReportEvaluation ( BaseModel ):
"""Схема для оценки финансового отчета.""
clarity_and_structure_score: int = Field(description= "Оценка от 1 до 10 по организации, структуре и ясности отчета." )
analytical_depth_score: int = Field(description= "Оценка от 1 до 10 по глубине и качеству анализа в каждом разделе." )
completeness_score: int = Field(description= "Оценка от 1 до 10 по тому, насколько хорошо отчет удовлетворил все части запроса пользователя." )
justification: str = Field(description= "Краткое обоснование оценок." )
При оценке разница очевидна. Монолитный агент может получить около 6 или 7 баллов. Однако наша команда из нескольких агентов получает гораздо более высокие оценки.
--- Оценка отчета многоагентной команды ---
{
'clarity_and_structure_score': 9,
'analytical_depth_score': 8,
'completeness_score': 9,
'justification': "Отчет исключительно хорошо структурирован, с четкими, отдельными разделами для каждого типа анализа. Каждый раздел содержит достаточно подробную информацию от экспертов. Выводы в заключении логичны и хорошо подкреплены предыдущими отчетами специалистов."
}
Из полученных результатов видно, что для сложных задач, которые можно разбить на части…
Команда специалистов почти всегда превзойдёт одного универсального специалиста.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 34
PEV (Планировщик-Исполнитель-Верификатор)
Наш агент планирования хорошо работает, когда путь ясен: он составляет план и следует ему. Но есть одно скрытое предположение…
Что происходит, когда что-то идёт не так? Если инструмент даёт сбой, API недоступен или поиск выдаёт некорректные результаты, стандартный планировщик просто передаёт ошибку дальше, что приводит к сбою или бессмысленному результату.
PEV (Планировщик-Исполнитель-Верификатор) — это простое, но мощное усовершенствование шаблона планирования, добавляющее критически важный уровень контроля качества и самокоррекции.
PEV важен для построения надежных и отказоустойчивых рабочих процессов. Он используется везде, где агент взаимодействует с внешними инструментами, которые могут быть ненадежными. .
Вот как это работает…
Нажмите Enter или щелкните, чтобы просмотреть изображение в полном размере.
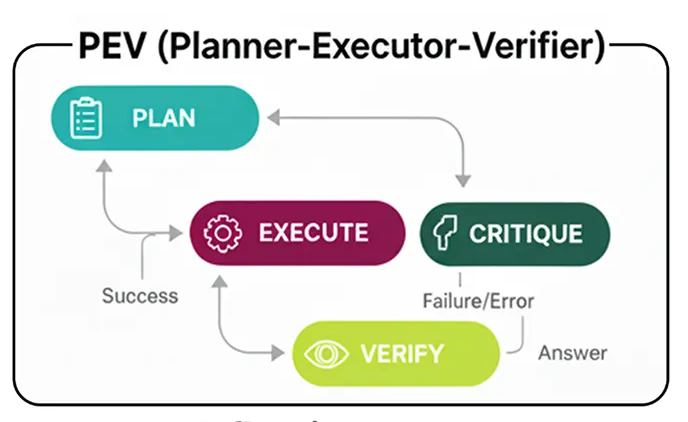
PEV (Создано)
Фарид Хан
)
План: Агент «Планировщик» создает последовательность шагов, как и раньше.
Выполнить: Агент «Исполнитель» берет на себя следующую задачу. шагу плана и вызывает инструмент.
Проверка: Это новый этап. Агент «Проверяющий» анализирует результаты работы инструмента. Он проверяет правильность, релевантность и наличие ошибок.
Маршрутизация и итерация: на основе решения верификатора:
Если этап пройден успешно , агент переходит к следующему этапу плана.
Если на этом этапе произошел сбой , агент возвращается к Планировщику для создания нового плана , теперь уже зная о сбое.
Если план выполнен, он доводится до конца.
Чтобы это действительно продемонстрировать, нам нужен инструмент, который может дать сбой. Поэтому мы создадим специальный flaky_web_searchинструмент, который будет намеренно возвращать сообщение об ошибке для конкретного запроса.
def flaky_web_search(query: str) -> str:
"" "Инструмент веб-поиска, который намеренно выдает ошибку при выполнении определенного запроса." ""
console. print (f "--- ИНСТРУМЕНТ: Поиск '{query}'... ---" )
if "количество сотрудников" in query. lower ():
console. print ( "--- ИНСТРУМЕНТ: [жирным красным]Имитация сбоя API![/жирным красным] ---" )
return "Ошибка: Не удалось получить данные. Конечная точка API в данный момент недоступна."
else :
return search_tool.invoke({ "query" : query})
Теперь перейдём к сути паттерна PEV: узел verifier_node. Единственная задача этого узла — проанализировать результат работы предыдущего инструмента и решить, был ли это успех или неудача.
class VerificationResult ( BaseModel ):
"""Схема выходных данных верификатора."""
is_successful: bool = Field(description= "True, если выполнение инструмента было успешным и данные действительны." )
reasoning: str = Field(description= "Обоснование решения о проверке." )
def verifier_node ( state: PEVState ):
"""Проверяет последний результат работы инструмента на наличие ошибок."""
console. print ( "--- ПРОВЕРКА: Проверка результата последнего инструмента... ---" )
verifier_llm = llm.with_structured_output(VerificationResult)
prompt = f"Проверьте, является ли следующий вывод инструмента успешным, допустимым результатом или сообщением об ошибке. Задача была ' {state[ 'user_request' ]} '.\n\nВывод инструмента: ' {state[ 'last_tool_result' ]} '"
verification = verifier_llm.invoke(prompt)
console. print ( f"--- ПРОВЕРКА: Результат проверки: ' { 'Успех' , если verification.is_successful , иначе 'Неудача' } ' ---" )
if verification.is_successful:
return { "intermediate_steps" : state[ "intermediate_steps" ] + [state[ 'last_tool_result' ]]}
else :
# Если проверка не удалась, добавляем причину сбоя и очищаем план, чтобы запустить перепланирование
return { "plan" : [], "intermediate_steps" : state[ "intermediate_steps" ] + [ f"Проверка не удалась: {state[ 'last_tool_result' ]} " ]}
Подготовив верификатор, мы можем подключить весь граф. Ключевым моментом здесь является логика маршрутизатора. После выполнения заданий verifier_node, если план внезапно оказывается пустым (потому что верификатор его очистил), наш маршрутизатор знает, что нужно отправить агента обратно, чтобы planner_nodeповторить попытку.
class PEVState ( TypedDict ):
user_request: str
plan: Optional [ List [ str ]]
last_tool_result: Optional [ str ]
intermediate_steps: List [ str ]
final_answer: Optional [ str ]
retries: int
# ... (определения planner_node, executor_node и synthesizer_node аналогичны предыдущим) ...
def pev_router ( state: PEVState ):
"""Выполнение маршрутов на основе проверки и статуса плана."""
if not state[ "plan" ]:
# Проверяем, пуст ли план, потому что проверка не удалась
if state[ "intermediate_steps" ] and "Verification Failed" in state[ "intermediate_steps" ][- 1 ]:
console. print ( "--- МАРШРУТИЗАТОР: Проверка не удалась. Перепланирование... ---" )
return "plan"
else :
console. print ( "--- МАРШРУТИЗАТОР: Планирование завершено. Переходим к синтезатору. ---" )
return "synthesize"
else :
console. print ( "--- МАРШРУТИЗАТОР: План содержит еще шаги. Продолжение выполнения. ---" )
return "execute"
pev_graph_builder = StateGraph(PEVState)
pev_graph_builder.add_node( "plan" , pev_planner_node)
pev_graph_builder.add_node( "execute" , pev_executor_node)
pev_graph_builder.add_node( "verify" , verifier_node)
pev_graph_builder.add_node( "synthesize" , synthesizer_node)
pev_graph_builder.set_entry_point( "plan" )
pev_graph_builder.add_edge( "plan" , "execute" )
pev_graph_builder.add_edge( "execute" , "verify" )
pev_graph_builder.add_conditional_edges( "verify" , pev_router)
pev_graph_builder.add_edge( "synthesize" , END)
pev_agent_app = pev_graph_builder.компилировать ()

Архитектура PEV (создано компанией...)
Фарид Хан
)
Теперь перейдём к решающему тесту. Мы дадим нашему агенту PEV задачу, которая потребует от него вызова нашего flaky_web_searchинструмента с запросом, который, как мы знаем, завершится ошибкой. Простой агент Planner-Executor здесь бы сломался.
flaky_query = "Каковы были расходы Apple на НИОКР в прошлом финансовом году и каково было общее количество сотрудников? Рассчитайте расходы на НИОКР на одного сотрудника."
console. print ( f"[bold green]Тестирование агента PEV на нестабильном запросе:[/bold green]\n' {flaky_query} '\n" )
initial_pev_input = { "user_request" : flaky_query, "intermediate_steps" : [], "retries" : 0 }
final_pev_output = pev_agent_app.invoke(initial_pev_input)
console. print ( "\n--- [bold green]Итоговый вывод от агента PEV[/bold green] ---" )
console. print (Markdown(final_pev_output[ 'final_answer' ]))
Тестирование агента PEV на том же нестабильном запросе:
«Каковы были расходы Apple на НИОКР в прошлом финансовом году и какова была общая численность сотрудников? Рассчитайте
расходы на НИОКР на одного сотрудника».
--- (PEV) ПЛАНИРОВЩИК: Создание/редактирование плана (повторов 0)... ---
--- (PEV) ИСПОЛНИТЕЛЬ: Выполнение следующего шага... ---
--- ИНСТРУМЕНТ: Поиск «расходы Apple на НИОКР в прошлом финансовом году»... ---
--- ПРОВЕРЯЮЩИЙ: Проверка последнего результата работы инструмента... ---
--- ПРОВЕРЯЮЩИЙ: Оценка «Успех» ---
...
План 1: Агент составляет план: ["Apple R&D spend...", "Apple total employee count"].
Выполнение и сбой: Проект получает финансирование на НИОКР, но employee countпоиск обращается к нашему нестабильному инструменту и возвращает ошибку.
Проверка и перехват: система verifier_nodeполучает сообщение об ошибке, корректно определяет её как сбой и сбрасывает план.
Маршрутизатор и перепланирование: Маршрутизатор видит пустой план и сообщение об ошибке и отправляет агента обратно на planner_node.
План 2: Планировщик, теперь понимая, что расчет общего числа сотрудников Apple провалился, создает новый, более продуманный план, возможно, пытаясь web_search('Apple number of employees worldwide')...
Выполнение и успех: Этот новый план работает, и агент получает все необходимые данные.
В итоге получился правильный результат вычислений. Агент не просто сдался; он обнаружил проблему, придумал новый подход и добился успеха.
Для формализации этого вопроса нашему магистру права в качестве судьи необходимо оценить его надежность.
class RobustnessEvaluation ( BaseModel ):
"""Схема для оценки устойчивости агента и обработки ошибок."""
task_completion_score: int = Field(description= "Оценка от 1 до 10 за выполнение задачи." )
error_handling_score: int = Field(description= "Оценка от 1 до 10 за способность агента обнаруживать ошибки и восстанавливаться после них." )
justification: str = Field(description= "Краткое обоснование оценок." )
Стандартный агент «Планировщик-Исполнитель» получил бы ужасный результат error_handling_score. Наш же агент PEV, напротив, превосходен.
--- Оценка устойчивости агента PEV ---
{
'task_completion_score' : 8 ,
'error_handling_score' : 10 ,
'justification' : "Агент продемонстрировал идеальную устойчивость. Он успешно выявил сбой инструмента с помощью своего верификатора, запустил цикл перепланирования и сформулировал новый запрос для обхода проблемы. Это образцовый пример восстановления после ошибки."
}
Как видите, архитектура PEV — это не просто получение правильного ответа, когда всё идёт хорошо…
Речь идёт о том, чтобы не дать неправильный ответ, когда что-то пойдёт не так.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 35
Древо мыслей (ToT)
Метод PEV позволяет справиться с отказом инструмента и повторить попытку по новому плану. Однако само планирование остается линейным. Оно создает единый пошаговый план и следует ему.
Что происходит, когда проблема представляет собой не прямую дорогу, а скорее лабиринт с тупиками и множеством возможных путей?
Здесь вступает в дело архитектура « Древо мыслей» (Tree-of-Thoughts, ToT) . Вместо того чтобы генерировать единую линию рассуждений, агент ToT исследует множество путей одновременно. Он генерирует несколько возможных следующих шагов, оценивает их, отбрасывает неподходящие и продолжает исследовать наиболее перспективные ветви.
В крупных системах искусственного интеллекта технология ToT помогает решать сложные задачи, такие как планирование маршрутов, составление расписаний или непростые головоломки.
Вот как работает обычный процесс обучения тренеров…
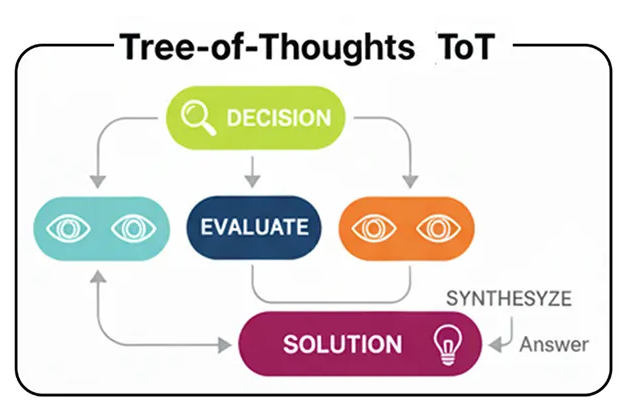
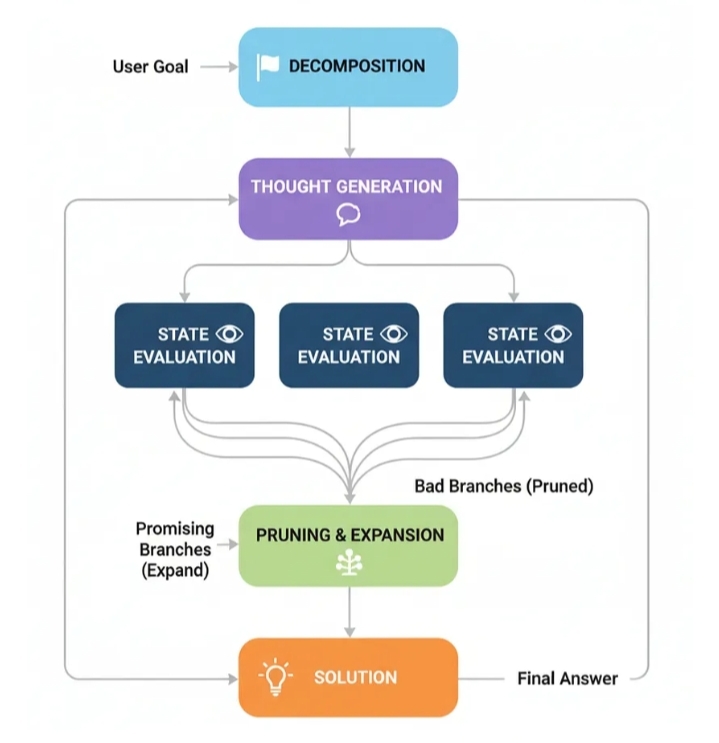
Процесс TOT (Создано компанией...)
Фарид Хан
)
Декомпозиция: Проблема разбивается на ряд шагов или «мыслей».
Генерация мыслей: Для текущего состояния агент генерирует несколько потенциальных следующих шагов. Это создает ветви нашего «дерева мыслей».
Оценка состояния: Каждый новый потенциальный шаг оценивается критиком или функцией проверки. Эта проверка определяет, является ли ход допустимым, идет ли он навстречу прогрессу или же это просто движение по кругу.
Обрезка и расширение: Затем агент «обрезает» плохие ветви (недействительные или бесперспективные) и продолжает процесс с оставшихся хороших ветвей.
Решение: Этот процесс продолжается до тех пор, пока одна из ветвей не достигнет конечной цели.
Чтобы продемонстрировать ToT, нам нужна задача, которую нельзя решить по прямой линии, — головоломка «Волк, Коза и Капуста», позволяющая переправиться через реку. Она идеально подходит, поскольку требует неочевидных ходов (например, возвращения чего-либо обратно) и имеет недопустимые состояния, которые могут поставить в тупик простой логический механизм.
Сначала мы определим правила головоломки, используя пидантическую модель для состояния и функцию проверки корректности (чтобы ничего не было съедено).
class PuzzleState ( BaseModel ):
"Представляет состояние головоломки "Волк, Коза и Капуста."
left_bank: set [ str ] = Field(default_factory= lambda : { "wolf" , "goat" , "cabbage" })
right_bank: set [ str ] = Field(default_factory= set )
boat_location: str = "left"
move_description: str = "Начальное состояние."
def is_valid ( self ) -> bool :
"""Проверяет, является ли текущее состояние допустимым."""
# Проверяем левый берег на наличие недопустимых пар, если лодка находится справа.
if self.boat_location == "right" :
if "wolf" in self.left_bank and "goat" in self.left_bank: return False
if "goat" in self.left_bank and "cabbage" in self.left_bank: return False
# Проверяем правый берег на наличие недопустимых пар, если лодка находится слева.
if self.boat_location == "left" :
if "wolf" in self.right_bank and "goat" in self.right_bank: return False
if "goat" in self.right_bank and "cabbage" in self.right_bank: return False
return True
def is_goal ( self ) -> bool :
"""Проверяет, выиграли ли мы."""
return self.right_bank == { "wolf" , "коза" , "капуста" }
# Делаем состояние хешируемым, чтобы мы могли обнаруживать циклы
def __hash__ ( self ):
return hash (( frozenset (self.left_bank), frozenset (self.right_bank), self.boat_location))
Теперь перейдём к сути агента ToT. Состояние нашего графа будет содержать все активные пути в нашем дереве мыслей. Узел expand_pathsбудет генерировать новые ветви, а также prune_pathsобрезать дерево, удаляя все пути, которые заходят в тупик или образуют замкнутый круг.
class ToTState ( TypedDict ):
problem_description: str
active_paths: List [ List [PuzzleState]] # Это наше "древовидное"
решение: Optional [ List [PuzzleState]]
def expand_paths ( state: ToTState ) -> Dict [ str , Any ]:
"""Генератор мыслей. Расширяет каждый активный путь всеми допустимыми следующими ходами."""
console. print ( "--- Расширение путей ---" )
new_paths = []
for path in state[ 'active_paths' ]:
last_state = path[- 1 ]
# Получаем все допустимые следующие состояния из текущего состояния
possible_next_states = get_possible_moves(last_state) # Предполагая, что get_possible_moves определен
for next_state in possible_next_states:
new_paths.append(path + [next_state])
console. print ( f"[cyan]Расширено до { len (new_paths)} потенциальных путей.[/cyan]" )
return { "active_paths" : new_paths}
def prune_paths ( state: ToTState ) -> Dict [ str , Any ]:
"""Оценщик состояний. Удаляет недопустимые пути или пути, содержащие циклы."""
console.print ( "--- Удаление путей ---" )
pruned_paths = []
for path in state[ 'active_paths' ]:
# Проверка на циклы: если последнее состояние уже встречалось в пути
if path[ -1 ] in path[:- 1 ]:
continue # Найден цикл, удаляем этот путь
pruned_paths.append(path)
console. print ( f"[green]Сокращено до { len (pruned_paths)} допустимых, нециклических путей.[/green]" )
return { "active_paths" : pruned_paths}
# ... (соединение графа с условным ребром, проверяющим наличие решения) ...
workflow = StateGraph(ToTState)
workflow.add_node( "expand"
workflow.add_node( "prune" , prune_paths )

Архитектура ToT (создана)
Фарид Хан
)
Давайте запустим нашего агента ToT на этой головоломке. Простой агент, использующий метод «цепочки мыслей», мог бы решить её, если бы уже сталкивался с ней, но он лишь вспоминает решение. Наш агент ToT найдёт решение посредством систематического поиска.
проблема = "Фермер хочет пересечь реку с волком, козой и капустой..." console.print
( " --- 🌳 Запущен агент "Древо мыслей" ---" ) final_state = tot_agent.invoke({ "problem_description" : problem}, { "recursion_limit" : 15 }) console.print ( " \n--- ✅ Решение агента ToT ---" )
Траектория вывода показывает работу агента, методично исследующего головоломку.
--- Расширение путей ---
[голубой]Расширено до 1 потенциального пути.[/голубой]
--- Сокращение путей ---
[зеленый]Сокращено до 1 допустимого, нециклического пути.[/зеленый]
--- Расширение путей ---
[голубой]Расширено до 2 потенциальных путей.[/голубой]
--- Сокращение путей ---
[зеленый]Сокращено до 2 допустимых, нециклических путей.[/зеленый]
...
[жирный зеленый]Решение найдено![/жирный зеленый]
--- ✅ Решение агента ToT ---
1. Начальное состояние.
2. Переместить козу на правый берег.
3. Переместить пустую лодку на левый берег.
4. Переместить волка на правый берег.
5. Переместить козу на левый берег.
6. Переместить капусту на правый берег.
7. Переместить пустую лодку на левый берег.
8. Переместить козу на правый берег.
Агент нашел правильное решение из 8 шагов! Он не просто угадал; он систематически исследовал возможные варианты, отбрасывал неверные и нашел путь, который гарантированно оказался правильным. В этом и заключается сила ToT (Tool-to-T).
Для формализации этого вопроса мы будем использовать специалиста по праву в качестве судьи, который будет оценивать качество процесса рассуждений.
class ReasoningEvaluation ( BaseModel ):
"""Схема для оценки процесса рассуждений агента."""
solution_correctness_score: int = Field(description= "Оценка от 1 до 10, указывающая на правильность и корректность окончательного решения." )
reasoning_robustness_score: int = Field(description= "Оценка от 1 до 10, указывающая на надежность процесса рассуждений агента. Высокая оценка означает, что он систематически исследовал проблему, низкая — что он просто угадывал." )
justification: str = Field(description= "Краткое обоснование оценок." )
Простой агент, использующий метод «цепочки мыслей», может получить высокий балл за правильность, если ему повезет, но его показатель устойчивости будет низким. Наш же агент, использующий этот метод, получает высшие оценки.
--- Оценка процесса работы агента ToT ---
{
'solution_correctness_score' : 8 ,
'reasoning_robustness_score' : 9 ,
'justification' : "Процесс работы агента был абсолютно надежным. Он не просто давал ответ; он систематически исследовал дерево возможных вариантов, отсеивал неверные пути и гарантировал правильное решение. Это гораздо более надежный метод, чем однократное угадывание."
}
Мы видим, что агент ToT работает хорошо не случайно, а потому что его поиск является надежным.
Это делает его лучшим выбором для задач, требующих высокой надежности.
- Информация о материале
- Автор: Super User
- Категория: Шаблоны мультиагентных систем
- Просмотров: 32
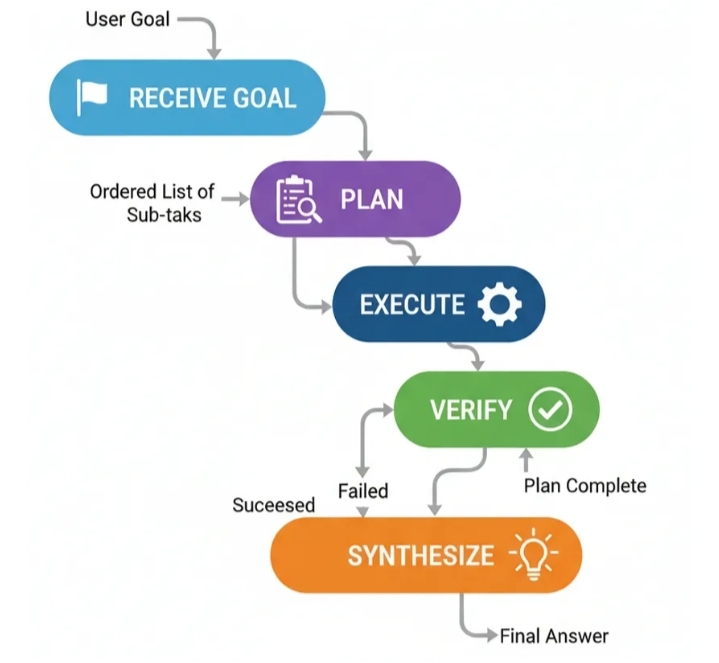
Планирование
Паттерн ReAct отлично подходит для исследования проблемы и поиска решений на ходу. Однако он может быть несколько неэффективным для задач, где шаги предсказуемы. Это как человек, спрашивающий дорогу по одному повороту за раз, вместо того, чтобы сначала посмотреть на всю карту. Вот тут-то и пригодится архитектура планирования .
Эта модель вносит важный элемент предвидения.
Вместо того чтобы реагировать шаг за шагом, специалист по планированию сначала составляет полный «план действий», прежде чем предпринимать какие-либо шаги.
В системах искусственного интеллекта планирование — это ваш главный инструмент для любого структурированного многоэтапного процесса. Подумайте о конвейерах обработки данных, генерации отчетов или любом рабочем процессе, где последовательность операций известна заранее. Это обеспечивает предсказуемость и эффективность, упрощая отслеживание и отладку поведения агента.
Давайте разберемся, как протекает этот процесс.
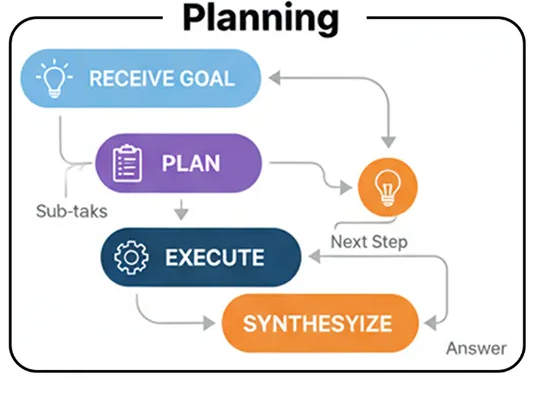
Подход к планированию (разработан)
Фарид Хан
)
Цель получения задания: Агенту дается сложное задание.
Планирование: Специальный компонент «Планировщик» анализирует цель и генерирует упорядоченный список подзадач, необходимых для ее достижения. Например: ["Find fact A", "Find fact B", "Calculate C using A and B"].
Выполнение: Компонент «Исполнитель» принимает план и последовательно выполняет каждую подзадачу, используя необходимые инструменты.
Синтез: После завершения всех этапов плана заключительный этап объединяет результаты выполненных шагов в целостный итоговый ответ.
Давайте начнём его строить.
Мы создадим три основных компонента: один planner_nodeдля разработки стратегии, один executor_nodeдля ее реализации и один synthesizer_nodeдля составления итогового отчета.
Для начала нам нужен выделенный модуль planner_node. Ключевым моментом здесь является очень четкая подсказка, которая указывает модулю LLM, что его задача — создать список простых, выполнимых шагов.
class Plan ( BaseModel ):
"""План вызовов инструментов для выполнения в ответ на запрос пользователя."""
steps: List [ str ] = Field(description= "Список вызовов инструментов, которые при выполнении ответят на запрос." )
class PlanningState ( TypedDict ):
user_request: str
plan: Optional [ List [ str ]]
intermediate_steps: List [ str ] # Будет хранить выходные данные инструментов
final_answer: Optional [ str ]
def planner_node ( state: PlanningState ):
"""Генерирует план действий для ответа на запрос пользователя."""
console. print ( "--- ПЛАНИРОВЩИК: Разложение задачи... ---" )
planner_llm = llm.with_structured_output(Plan)
prompt = f"""Вы — опытный планировщик. Ваша задача — создать пошаговый план для ответа на запрос пользователя.
Каждый шаг в плане должен представлять собой отдельный вызов инструмента `web_search`.
**Запрос пользователя:**
{state[ 'user_request' ]}
"""
plan_result = planner_llm.invoke(prompt)
console.print ( f " --- ПЛАНИРОВЩИК: Сгенерированный план: {plan_result.steps} ---" )
return { "plan" : plan_result.steps}
Далее, executor_node. Это простой обработчик, который просто выполняет следующий шаг из плана, запускает инструмент и добавляет результат в наше состояние.
def executor_node ( state: PlanningState ):
"""Выполняет следующий шаг в плане."""
console. print ( "--- EXECUTOR: Выполняется следующий шаг... ---" )
next_step = state[ "plan" ][ 0 ]
# В реальном приложении вы бы анализировали имя инструмента и аргументы. Здесь мы предполагаем 'web_search'.
query = next_step.replace( "web_search('" , "" ).replace( "')" , "" )
result = search_tool.invoke({ "query" : query})
return {
"plan" : state[ "plan" ][ 1 :], # Извлекаем выполненный шаг
"intermediate_steps" : state[ "intermediate_steps" ] + [result]
}
Теперь нам просто нужно соединить их в граф. Маршрутизатор проверит, остались ли в плане какие-либо шаги. Если да, он вернется к исполнителю. В противном случае он перейдет к заключительному шагу synthesizer_node(который мы можем повторно использовать из предыдущего шаблона) для генерации ответа.
def planning_router ( state: PlanningState ):
"""Маршрутизирует маршрут к исполнителю или синтезатору на основе плана."""
if not state[ "plan" ]:
console. print ( "--- МАРШРУТИЗАТОР: Планирование завершено. Переходим к синтезатору. ---" )
return "synthesize"
else :
console. print ( "--- МАРШРУТИЗАТОР: План содержит еще шаги. Продолжение выполнения. ---" )
return "execute"
planning_graph_builder = StateGraph(PlanningState)
planning_graph_builder.add_node( "plan" , planner_node)
planning_graph_builder.add_node( "execute" , executor_node)
planning_graph_builder.add_node( "synthesize" , synthesizer_node)
planning_graph_builder.set_entry_point( "plan" )
planning_graph_builder.add_conditional_edges( "plan" , planning_router)
planning_graph_builder.add_conditional_edges( "execute" , planning_router)
planning_graph_builder.add_edge( "synthesize" , END)

Планирование (создано)
Фарид Хан
)
Чтобы действительно увидеть разницу, давайте дадим нашему агенту задачу, для решения которой полезно предвидение. Агент ReAct может решить эту задачу, но его пошаговый процесс менее прямой.
plan_centric_query = """
Найдите население столиц Франции, Германии и Италии.
Затем рассчитайте их суммарное население.
"""
console. print ( f"[bold green]Тестирование агента планирования на запросе, ориентированном на план:[/bold green] ' {plan_centric_query} '\n" )
# Правильная инициализация состояния, особенно списка для промежуточных шагов
initial_planning_input = { "user_request" : plan_centric_query, "intermediate_steps" : []}
final_planning_output = planning_agent_app.invoke(initial_planning_input)
console. print ( "\n--- [bold green]Итоговый вывод от агента планирования[/bold green] ---" )
console. print (Markdown(final_planning_output[ 'final_answer' ]))
Разница в процессе очевидна сразу. Первое, что делает наш агент, — это излагает всю свою стратегию.
--- ПЛАНИРОВЩИК: Декомпозиция задачи... ---
--- ПЛАНИРОВЩИК: Сгенерирован план: ["web_search('население Парижа')", "web_search('население Берлина')", "web_search('население Рима')"] ---
--- МАРШРУТИЗАТОР: План содержит еще шаги. Продолжение выполнения. ---
--- ИСПОЛНИТЕЛЬ: Выполнение следующего шага... ---
...
Агент разработал подробный, четкий план, прежде чем предпринять какое-либо действие. Затем он методично выполнил этот план. Этот процесс более прозрачен и надежен, поскольку он следует четкому набору инструкций.
Чтобы формализовать это, мы воспользуемся услугами нашего магистра права в качестве судьи, но на этот раз мы оценим эффективность процесса .
class ProcessEvaluation ( BaseModel ):
"""Схема для оценки процесса решения проблем агентом."""
task_completion_score: int = Field(description= "Оценка от 1 до 10 за выполнение задачи." )
process_efficiency_score: int = Field(description= "Оценка от 1 до 10 за эффективность и прямолинейность процесса агента." )
justification: str = Field(description= "Краткое обоснование оценок." )
При оценке эффективности работы агента по планированию выделяется своей прямолинейностью.
--- Оценка процесса работы агента по планированию ---
{
'task_completion_score': 8,
'process_efficiency_score': 9,
'justification': "Агент заранее разработал четкий, оптимальный план и выполнил его без каких-либо лишних шагов. Его процесс был очень прямым и эффективным для этой предсказуемой задачи."
}
Мы получаем хорошие оценки, а это значит, что наш подход создает правильную систему планирования, так что…
Когда путь к решению предсказуем, планирование предлагает более структурированный и эффективный подход, чем чисто реактивный.
planning_agent_app = planning_graph_builder.compile ( )
Страница 3 из 4
- Вы здесь:
-
Главная

- Шаблоны мультиагентных систем