
Создание 17 шаблонов агентного ИИ и их роль в крупномасштабных системах искусственного интеллекта.
Ансамблирование, мета-управление, ToT, рефлексивность, PEV и многое другое.
Вот некоторые из этих узоров:
- Многоагентная система , в которой несколько инструментов и агентов работают вместе для решения проблемы.
- Ансамблевая система принятия решений , в которой несколько агентов предлагают по одному ответу, а затем голосуют за лучший из них.
- Древо мыслей , в котором агент исследует множество различных путей рассуждений, прежде чем выбрать наиболее перспективное направление.
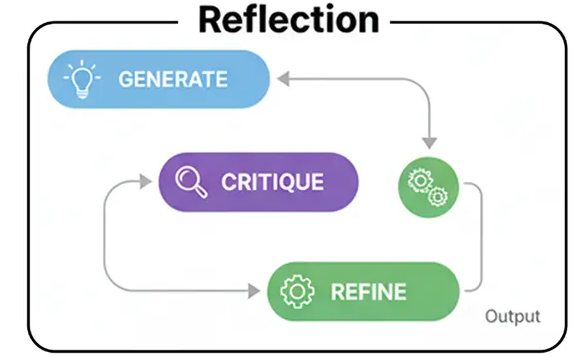
- Рефлексивный подход , при котором субъект способен распознать и признать то, чего он не знает.
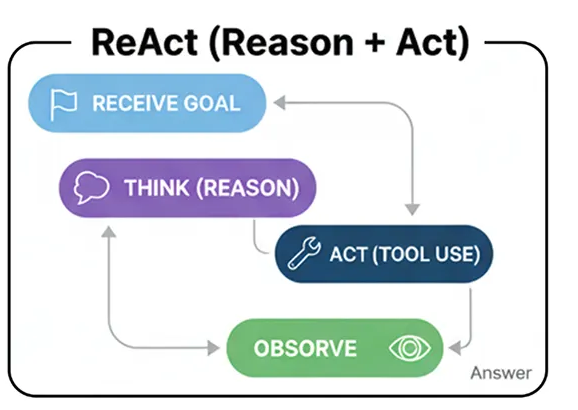
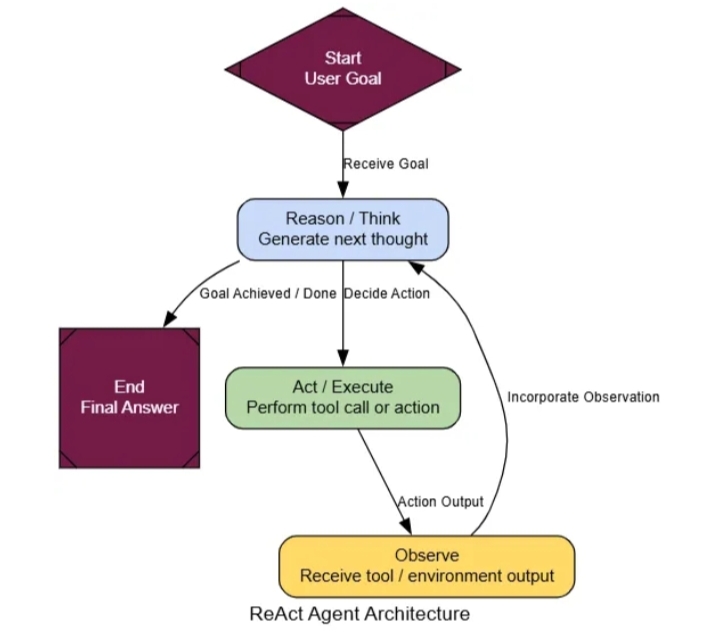
- Цикл ReAct , в котором агент попеременно думает, предпринимает действия, а затем снова думает, чтобы усовершенствовать свой процесс.
И их гораздо больше…
В этом блоге мы подробно рассмотрим различные типы агентных архитектур и покажем, какую уникальную роль каждая из них играет в полноценной системе искусственного интеллекта.
Мы визуально оценим важность каждой архитектуры, закодируем соответствующий рабочий процесс и проведем оценку, чтобы определить, действительно ли он улучшает производительность по сравнению с базовым вариантом.
Весь код доступен в моём репозитории на GitHub:
GitHub - FareedKhan-dev/all-agentic-architectures: Реализация более 17 агентных архитектур…
Реализация более 17 агентных архитектур, разработанных для практического применения на различных этапах развития систем искусственного интеллекта…
github.com
Кодовая база организована следующим образом:
all-agentic-architectures/
├── 01_reflection.ipynb
├── 02_tool_use.ipynb
├── 03_ReAct.ipynb
...
├── 06_PEV.ipynb
├── 07_blackboard.ipynb
├── 08_episodic_with_semantic.ipynb
├── 09_tree_of_thoughts.ipynb
...
├── 14_dry_run.ipynb
├── 15_RLHF.ipynb
├── 16_cellular_automata.ipynb
└── 17_reflexive_metacognitive.ipynb
Оглавление
- Настройка среды
- Отражение
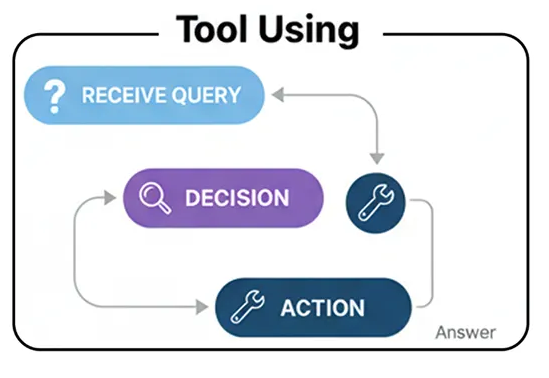
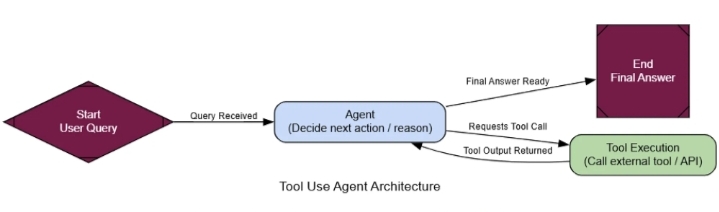
- Использование инструмента
- Реагировать (Разум + Действие)
- Планирование
- PEV (Планировщик-Исполнитель-Верификатор)
- Древо мыслей (ToT)
- Многоагентные системы
- Мета-контроллер
- Доска
- Принятие решений коллективом
- Эпизодическая + Семантическая память
- Память графа (мировой модели)
- Цикл самосовершенствования (аналогия RLHF)
- Тренировочная страховочная система
- Симулятор (ментальная модель в контуре управления)
- Рефлексивная метакогнитивная
- Клеточные автоматы
- Объединение архитектурных решений
Настройка среды
Прежде чем приступить к построению каждой архитектуры, нам необходимо определить основные параметры и четко понимать, что мы используем, почему нужны те или иные модули, модели и как все это взаимодействует друг с другом.
Нам известно, что LangChain , LangGraph и LangSmith — это практически стандартные модули для создания любой серьезной системы RAG или агентной системы. Они предоставляют все необходимое для построения, оркестрации и, что наиболее важно, для понимания того, что происходит внутри наших агентов, когда ситуация усложняется, поэтому мы и остановились на этих трех.
Первым делом нужно импортировать основные библиотеки. Таким образом, мы избежим повторения этих действий в дальнейшем и сохраним систему в чистоте и порядке. Давайте это сделаем.
import os
from typing import List , Dict , Any , Optional , Annotated, TypedDict
from dotenv import load_dotenv # Загрузка переменных окружения из файла .env
# Pydantic для моделирования/проверки данных
from pydantic import BaseModel, Field
# Компоненты LangChain и LangGraph
from langchain_nebius import ChatNebius # Оболочка Nebius LLM
from langchain_tavily import TavilySearch # Интеграция инструмента поиска Tavily
from langchain_core.prompts import ChatPromptTemplate # Для структурирования подсказок
from langgraph.graph import StateGraph, END # Создание графа конечного автомата
from langgraph.prebuilt import ToolNode, tools_condition # Предварительно созданные узлы и условия
# Для красивого вывода в консоль
from rich.console import Console # Стилизация консоли
from rich.markdown import Markdown # Отображение Markdown в терминале
Итак, давайте быстро разберемся, почему мы используем именно эти три варианта.
- LangChain — это наш набор инструментов, предоставляющий нам основные строительные блоки, такие как подсказки, определения инструментов и оболочки LLM.
- LangGraph — это наш механизм оркестровки, объединяющий все элементы в сложные рабочие процессы с помощью циклов и ветвлений.
- LangSmith — это наш отладчик, отображающий визуальную трассировку каждого шага, который предпринимает агент, что позволяет нам быстро выявлять и исправлять проблемы.
Мы будем работать с модулями LLM с открытым исходным кодом от таких поставщиков, как Nebius AI или Together AI . Преимущество в том, что они работают точно так же, как стандартный модуль OpenAI, поэтому нам не нужно многое менять, чтобы начать работу. А если мы захотим запускать всё локально, мы просто заменим его чем-нибудь вроде Ollama .
Чтобы наши агенты не были привязаны к статическим данным, мы предоставляем им доступ к API Tavily для поиска в реальном времени (1000 кредитов в месяц, думаю, достаточно для тестирования). Таким образом, они смогут…
Они активно ищут информацию самостоятельно, что позволяет сосредоточиться на реальном логическом мышлении и использовании инструментов.
Далее нам нужно настроить переменные окружения. Здесь мы будем хранить конфиденциальную информацию, например, ключи API. Для этого создайте файл с именем .envв той же директории и поместите в него ваши ключи, например:
# Ключ API для Nebius LLM (используется с ChatNebius)
NEBIUS_API_KEY= "ваш_ключ_API_nebius_здесь"
# Ключ API для LangSmith (платформа мониторинга/телеметрии LangChain)
LANGCHAIN_API_KEY= "ваш_ключ_API_langsmith_здесь"
# Ключ API для инструмента поиска Tavily (используется с интеграцией TavilySearch)
TAVILY_API_KEY= "ваш_ключ_API_tavily_здесь"
После того как .envфайл будет настроен, мы сможем легко интегрировать эти ключи в наш код, используя dotenvмодуль, который мы импортировали ранее.
load_dotenv() # Загрузка переменных окружения из файла .env
# Включение трассировки LangSmith для мониторинга/отладки
os.environ[ "LANGCHAIN_TRACING_V2" ] = "true"
os.environ[ "LANGCHAIN_PROJECT" ] = "Реализация 17 агентных архитектур" # Название проекта для группировки трассировок
# Проверка наличия всех необходимых ключей API
for key in [ "NEBIUS_API_KEY" , "LANGCHAIN_API_KEY" , "TAVILY_API_KEY" ]:
if not os.environ.get(key): # Если ключ не найден в переменных окружения
print ( f" {ключ} не найден. Пожалуйста, создайте файл .env и установите его." )
Теперь, когда наша базовая конфигурация готова, мы можем начать создавать каждую архитектуру по отдельности, чтобы посмотреть, как они себя показывают и где они наиболее целесообразны в крупномасштабной системе искусственного интеллекта.