
Наш предыдущий агент стал большим шагом вперед. Он может использовать инструменты для получения данных в режиме реального времени, что очень важно. Проблема в том, что это, по сути, одноразовая операция: он решает, что ему нужен инструмент, вызывает его один раз, а затем пытается ответить.
Но что происходит, когда проблема становится более сложной и требует для решения множества взаимозависимых шагов?
ReAct (Reason + Act) — это создание цикла. Он позволяет агенту динамически обдумывать дальнейшие действия, например, выполнять операцию (например, вызывать инструмент), наблюдать за результатом, а затем использовать эту новую информацию для повторного анализа . Это переход от статического механизма вызова инструментов к адаптивному механизму решения проблем.
В любой системе искусственного интеллекта ReAct — это основной шаблон для решения задач, требующих многошагового логического вывода.
Давайте разберемся, как протекает этот процесс.
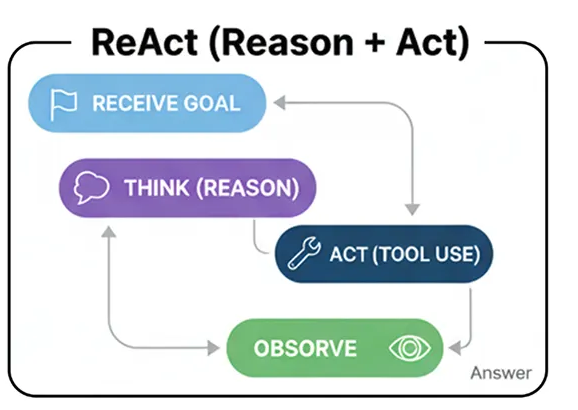
Рабочий процесс ReAct (создан пользователем)
Фарид Хан
)
Цель получения: Агенту поручают сложную задачу, которую нельзя решить за один шаг.
Мышление (Размышление): Агент генерирует мысль, например: «Чтобы ответить на этот вопрос, мне сначала нужно найти информацию X».
Действие: Исходя из этой мысли, оно выполняет действие, например, вызывает инструмент поиска по запросу «X».
Обратите внимание: агент получает результат для параметра 'X' обратно от инструмента.
Повторение: система берет новую информацию и возвращается к шагу 2, думая: «Хорошо, теперь, когда у меня есть X, мне нужно использовать его, чтобы найти Y». Этот цикл продолжается до тех пор, пока не будет достигнута конечная цель.
Хорошая новость в том, что мы уже создали большую часть компонентов. Мы будем повторно использовать AgentState, web_search, и tool_node. Единственное изменение в нашей логике графа: после tool_nodeвыполнения мы отправляем результат обратно в agent_nodeвместо завершения. Это создает цикл рассуждений, позволяя агенту просматривать результаты и выбирать следующий шаг.
def react_agent_node ( state: AgentState ):
"""Узел агента, который думает и принимает решение о следующем шаге."""
console. print ( "--- REACT AGENT: Thinking... ---" )
response = llm_with_tools.invoke(state[ "messages" ])
return { "messages" : [response]}
# Граф ReAct с характерным циклом
react_graph_builder = StateGraph(AgentState)
react_graph_builder.add_node( "agent" , react_agent_node)
react_graph_builder.add_node( "tools" , tool_node) # Мы повторно используем tool_node из предыдущего примера
react_graph_builder.set_entry_point( "agent" )
react_graph_builder.add_conditional_edges(
"agent" ,
# Мы можем повторно использовать ту же функцию маршрутизатора
router_function,
# Теперь карта определяет логику маршрутизации
{ "call_tool" : "tools" , "__end__" : "__end__" }
)
# Это ключевое отличие: ребро идет от узла инструмента ОБРАТНО к агенту
react_graph_builder.add_edge( "tools" , "agent" )
react_agent_app = react_graph_builder. compile ()
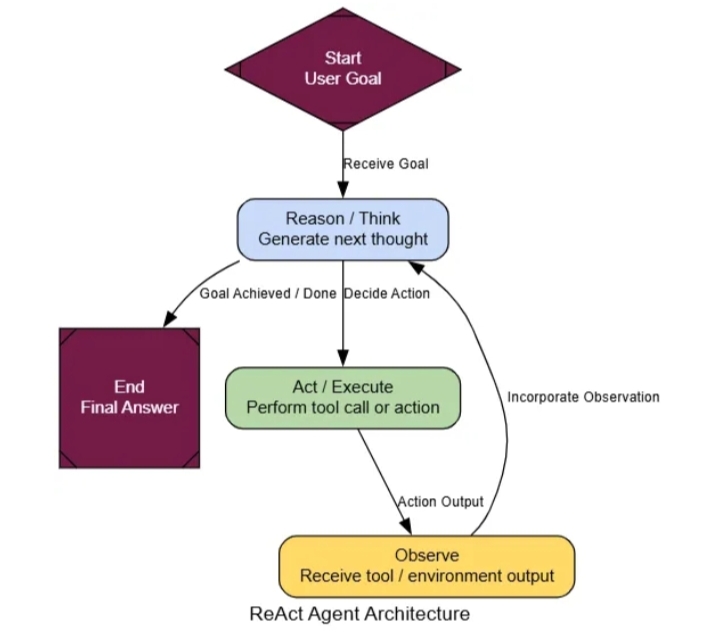
Архитектура ReAct (создано компанией...)
Фарид Хан
)
Вот и всё. Единственное реальное изменение — это react_graph_builder.add_edge("tools", "agent"). Эта единственная строка создаёт цикл и превращает нашего простого пользователя инструмента в динамического агента ReAct.
Чтобы понять, почему этот цикл так эффективен, давайте дадим ему задачу, которую невозможно решить за один раз — классический многошаговый вопрос. Простой агент, использующий инструмент, не справится с этим, потому что он не может связать шаги воедино.
multi_step_query = "Кто является нынешним генеральным директором компании, создавшей научно-фантастический фильм «Дюна», и каков был бюджет последнего фильма этой компании?" console.print
( f "[жирный желтый]Тестирование агента ReAct на многошаговом запросе:[/жирный желтый] ' {multi_step_query} '\n" ) final_react_output = None # Потоковая передача вывода для просмотра пошагового обоснования для chunk в react_agent_app.stream({ "messages" : [( "user" , multi_step_query)]}, stream_mode= "values" ): final_react_output = chunk console.print ( f"--- [жирный фиолетовый] Обновление текущего состояния[/жирный фиолетовый] ---" ) chunk[ 'messages' ][- 1 ].pretty_print() console.print ( " \n" ) console. print ( "\n--- [жирный зеленый]Итоговый вывод от агента ReAct[/жирный зеленый] ---" ) console.print ( Markdown (final_react_output[ 'messages' ][- 1 ].content))
--- Сообщение от человека ---
Кто является генеральным директором компании, снявшей «Дюну»...
--- Агент REACT: Размышляет... ---
--- Маршрутизатор: Вызов инструмента...
--- Сообщение от ИИ ---
Вызовы инструмента: web_search...
Аргументы: query: текущий генеральный директор компании, снявшей «Дюну»...
--- Сообщение от инструмента ---
[{"title": "Дюна: Часть третья - Википедия", "content": "Легендарный генеральный директор Джошуа Гроде..."}]
--- Агент REACT: Размышляет... ---
--- Маршрутизатор: Завершение...
--- Итоговый результат ---
Генеральный директор компании, снявшей «Дюну», - Джошуа Гроде...
Бюджет последнего фильма не найден...
Когда мы запускаем это, трассировка выполнения агента показывает гораздо более интеллектуальный процесс. Он не просто выполняет один поиск. Вместо этого он логически просчитывает решение проблемы:
Мысль 1: «Сначала мне нужно выяснить, какая компания сняла фильм «Дюна»».
Действие 1: Оно вызывает web_search('production company for Dune movie').
Наблюдение 1: Оно возвращает "Легендарное развлечение".
Мысль 2: «Ладно, теперь мне нужен генеральный директор Legendary Entertainment».
Действие 2: Оно звонит web_search('CEO of Legendary Entertainment')и так далее, пока не соберет все части.
Для формализации улучшений мы можем снова использовать нашего магистра права в качестве судьи, на этот раз сосредоточившись на выполнении задач.
class TaskEvaluation ( BaseModel ):
"""Схема для оценки способности агента выполнить задачу."""
task_completion_score: int = Field(description= "Оценка от 1 до 10, показывает, успешно ли агент выполнил все части запроса пользователя." )
reasoning_quality_score: int = Field(description= "Оценка от 1 до 10, показывает логический поток и процесс рассуждения, продемонстрированные агентом." )
justification: str = Field(description= "Краткое обоснование оценок." )
def evaluate_agent_output ( query: str , agent_output: dict ):
"""Запускает LLM-as-a-Judge для оценки итоговой производительности агента."""
trace = "\n" .join([ f" {m. type } : {m.content} " for m in agent_output[ 'messages' ]])
prompt = f"""Вы эксперт" Оцените работу агентов ИИ. Оцените производительность следующего агента в заданной задаче по шкале от 1 до 10. Оценка 10 означает, что задача выполнена идеально. Оценка 1 означает полный провал.
**Задача пользователя:**
{query}
**Полная трассировка разговора агента:**
```
{trace}
``` {data-source-line= "108" }
"""
judge_llm = llm.with_structured_output(TaskEvaluation)
return judge_llm.invoke(prompt)
Давайте посмотрим на результаты. Обычный агент, пытающийся выполнить это задание, получил бы очень низкий балл, поскольку ему не удалось бы собрать всю необходимую информацию. Однако наш агент ReAct показывает гораздо лучшие результаты.
--- Оценка результатов работы агента ReAct ---
{
'task_completion_score': 8,
'reasoning_quality_score': 9,
'justification': "Агент правильно разбил проблему на несколько этапов... Он успешно определил компанию, а затем и генерального директора. Хотя ему было сложно найти бюджет для последнего фильма, его логическое мышление было обоснованным, и он выполнил большую часть задачи."
}
Мы видим, что это reasoning_quality_scoreподтверждает логичность и обоснованность пошагового процесса, подтвержденную нашим судьей (магистром права).
Паттерн ReAct позволяет агенту решать подобные сложные, многоэтапные задачи, требующие динамического мышления.