Использование инструмента
Разработанный нами шаблон рефлексии отлично подходит для оттачивания внутреннего логического мышления агента.
Но что происходит, когда агенту нужна информация, которой он еще не располагает?
Без доступа к внешним инструментам LLM ограничена предварительно обученными параметрами, она может генерировать данные и рассуждать, но не может запрашивать новые данные или взаимодействовать с внешним миром. Вот тут-то и вступает в действие наша вторая архитектура, Tool Use.
В любой крупномасштабной системе искусственного интеллекта использование инструментов не является необязательным, а важным и обязательным компонентом. Они выступают в качестве моста между рассуждениями агента и данными из реального мира. Будь то бот службы поддержки, проверяющий статус заказа, или финансовый агент, получающий котировки акций в режиме реального времени.
Давайте разберемся, как протекает этот процесс.
-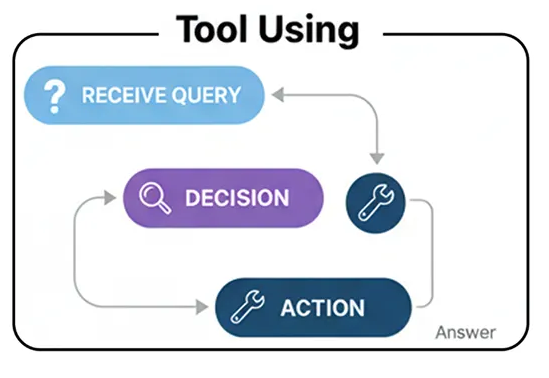
Инструмент, использующий рабочий процесс (создан пользователем)
Фарид Хан
)
Получение запроса: Агент получает запрос от пользователя.
Решение: Агент анализирует запрос и рассматривает доступные инструменты. Затем он решает, необходим ли тот или иной инструмент для точного ответа на вопрос.
Действие: Если требуется инструмент, агент формирует вызов этого инструмента, например, конкретной функции с правильными аргументами.
Наблюдение: Система выполняет вызов инструмента, и результат («наблюдение») отправляется обратно агенту.
Синтез: Агент берет выходные данные инструмента, объединяет их со своими собственными рассуждениями и генерирует окончательный, обоснованный ответ для пользователя.
Для этого нам нужно предоставить нашему агенту инструмент. Для этого мы будем использовать TavilySearchResultsинструмент, который дает нашему агенту доступ к поиску в интернете. Самая важная часть здесь — описание . LLM читает это описание на естественном языке, чтобы понять, что делает инструмент и когда его следует использовать, поэтому сделать его ясным и точным — ключ к успеху.
# Инициализируем инструмент. Мы можем установить максимальное количество результатов, чтобы контекст был кратким.
search_tool = TavilySearchResults(max_results= 2 )
# Крайне важно дать инструменту четкое имя и описание для агента.
search_tool.name = "web_search"
search_tool.description = "Инструмент, который можно использовать для поиска в интернете актуальной информации по любой теме, включая новости, события и текущие события."
tools = [search_tool]
Теперь, когда у нас есть функциональный инструмент, мы можем создать агента, который научится им пользоваться. Состояние агента, использующего инструмент, довольно простое: это всего лишь список сообщений, отслеживающий всю историю разговора.
class AgentState ( TypedDict ):
messages: Annotated[ list [AnyMessage], add_messages]
Далее нам необходимо сообщить LLM о предоставленных нам инструментах. Это критически важный шаг. Мы используем .bind_tools()метод, который, по сути, внедряет название и описание инструмента в системную подсказку LLM, позволяя ему самому решать, когда вызывать этот инструмент.
llm = ChatNebius(model= "meta-llama/Meta-Llama-3.1-8B-Instruct" , temperature= 0 )
# Привязываем инструменты к LLM, делая его совместимым с инструментами
llm_with_tools = llm.bind_tools(tools)
Теперь мы можем определить рабочий процесс нашего агента с помощью LangGraph. Нам нужны два основных узла: agent_node«мозг», который вызывает LLM для принятия решения о дальнейших действиях, и tool_node«руки», которые фактически выполняют инструмент.
def agent_node ( state: AgentState ):
"""Первичный узел, который вызывает LLM для принятия решения о следующем действии."""
console. print ( "--- АГЕНТ: Размышляет... ---" )
response = llm_with_tools.invoke(state[ "messages" ])
return { "messages" : [response]}
# ToolNode — это предварительно созданный узел из LangGraph, который выполняет инструменты
tool_node = ToolNode(tools)
После agent_nodeвыполнения заданий нам нужен маршрутизатор, чтобы определить, куда двигаться дальше. Если последнее сообщение агента содержит tool_callsатрибут, это означает, что он хочет использовать инструмент, поэтому мы направляем его к этому инструменту tool_node. В противном случае это означает, что у агента есть окончательный ответ, и мы можем завершить рабочий процесс.
def router_function ( state: AgentState ) -> str :
"""Проверяет последнее сообщение агента, чтобы решить, какой будет следующий шаг."""
last_message = state[ "messages" ][- 1 ]
if last_message.tool_calls:
# Агент запросил вызов инструмента
console. print ( "--- МАРШРУТИЗАТОР: Решение — вызвать инструмент. ---" )
return "call_tool"
else :
# Агент предоставил окончательный ответ
console. print ( "--- МАРШРУТИЗАТОР: Решение — завершить. ---" )
return "__end__"
Хорошо, у нас есть все необходимые элементы. Давайте соединим их в граф. Ключевым моментом здесь является условное ребро, которое использует наш механизм router_functionдля создания основного цикла рассуждений агента: agent-> router-> tool-> agent.
graph_builder = StateGraph(AgentState)
# Добавить узлы
graph_builder.add_node( "agent" , agent_node)
graph_builder.add_node( "call_tool" , tool_node)
# Установить точку входа
graph_builder.set_entry_point( "agent" )
# Добавить условный маршрутизатор
graph_builder.add_conditional_edges(
"agent" ,
router_function,
)
# Добавить ребро от узла инструмента обратно к агенту, чтобы завершить цикл
graph_builder.add_edge( "call_tool" , "agent" )
# Скомпилировать граф
tool_agent_app = graph_builder. compile ()
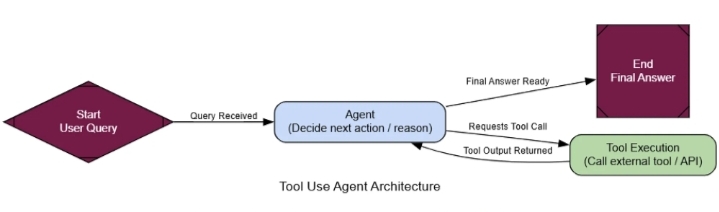
Архитектура вызовов инструментов (создана)
Теперь давайте протестируем это. Мы зададим ему вопрос, на который он никак не сможет ответить, используя свои обучающие данные, заставив его использовать инструмент веб-поиска для поиска ответа в реальном времени.
user_query = "Какие основные анонсы были сделаны на последнем мероприятии Apple WWDC?"
initial_input = { "messages" : [( "user" , user_query)]}
console. print ( f"[bold cyan]🚀 Запуск рабочего процесса использования инструментов для запроса:[/bold cyan] ' {user_query} '\n" )
for chunk in tool_agent_app.stream(initial_input, stream_mode= "values" ):
chunk[ "messages" ][- 1 ].pretty_print()
console. print ( "\n---\n" )
console. print ( "\n[bold green]✅ Рабочий процесс использования инструментов завершен![/bold green]" )
Давайте посмотрим на результат, чтобы увидеть ход мыслей агента.
================================== Сообщение от человека ==================================
Какие основные анонсы были сделаны на последнем мероприятии Apple WWDC?
---
--- АГЕНТ: Размышляю... ---
--- МАРШРУТИЗАТОР: Решение — вызвать инструмент. ---
=================================== Сообщение ИИ ===================================
Вызовы инструмента:
web_search (call_abc123)
Аргументы:
query: Последние анонсы Apple на WWDC
---
================================== Сообщение инструмента ==================================
Имя: web_search
[{"title": "WWDC 2025: Всё, что мы знаем...", "url": "...", "content": "Мероприятие Apple длилось час... мы подвели итоги всех анонсов... iOS 26, iPadOS 26, macOS Tahoe..."}]
---
--- АГЕНТ: Размышляет... ---
--- МАРШРУТИЗАТОР: Решение — завершить. ---
================================== Сообщение ИИ ===================================
Основные анонсы с последнего мероприятия Apple WWDC включают новый дизайн, который определит разработку iOS, iPadOS и macOS в следующем десятилетии, новые функции для iPhone... и обновления для всех платформ, включая iOS 26, iPadOS 26, CarPlay, macOS Tahoe...
Траектория движения наглядно демонстрирует логику агента:
Сначала система agent_nodeобдумывает ситуацию и решает, что ей необходимо выполнить поиск в интернете, после чего отправляет tool_callsзапрос.
Далее, программа tool_nodeвыполняет поиск и возвращает результат ToolMessageв исходном виде.
Наконец, алгоритм agent_nodeзапускается снова, на этот раз используя результаты поиска в качестве контекста для формирования окончательного, полезного ответа для пользователя.
Для формализации этого вопроса мы снова привлечем нашего магистра права в качестве судьи, но с критериями, специально разработанными для оценки использования инструментов.
class ToolUseEvaluation ( BaseModel ):
"""Схема для оценки использования инструментов агентом и его окончательного ответа."""
tool_selection_score: int = Field(description= "Оценка от 1 до 5, насколько агент выбрал правильный инструмент для задачи." )
tool_input_score: int = Field(description= "Оценка от 1 до 5, насколько хорошо были сформированы и релевантны входные данные для инструмента." )
synthesis_quality_score: int = Field(description= "Оценка от 1 до 5, насколько хорошо агент интегрировал выходные данные инструмента в свой окончательный ответ." )
justification: str = Field(description= "Краткое обоснование оценок." )
Когда мы запускаем проверку на основе полной трассировки разговора, мы получаем структурированную оценку.
--- Оценка эффективности использования инструмента ---
{
'tool_selection_score' : 5 ,
'tool_input_score' : 5 ,
'synthesis_quality_score' : 4 ,
'justification' : "Агент ИИ правильно использовал инструмент веб-поиска для поиска релевантной информации... Вывод инструмента был корректным и релевантным... агент ИИ мог бы лучше обработать информацию..."
}
Высокие баллы свидетельствуют о том, что наш агент не просто вызывает инструмент, а действительно эффективно его использует.
Она правильно определяла, когда следует искать, что искать и как использовать результаты. Эта архитектура является фундаментальным строительным блоком практически для любого практического ИИ-помощника.