Отражение
Итак, первая архитектура, которую мы рассмотрим, — это рефлексия . Это, пожалуй, самый распространенный и основополагающий шаблон, который вы видите в агентных рабочих процессах.
Речь идёт о том, чтобы дать агенту возможность отступить на шаг назад, оценить свою собственную работу и улучшить её.
В крупномасштабной системе искусственного интеллекта этот подход идеально подходит для любого этапа, где качество генерируемого результата имеет решающее значение. Подумайте о таких задачах, как генерация сложного кода, написание подробных технических отчетов — везде, где простой, черновой вариант ответа недостаточно хорош и может привести к реальным проблемам.
Давайте разберемся, как протекает этот процесс.
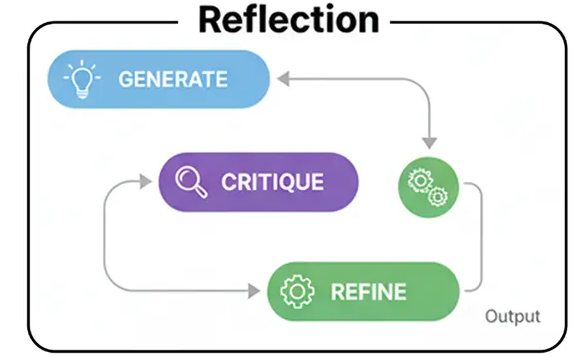
- Создание: Агент принимает запрос пользователя и создает первоначальный черновик или решение. Это его первая, неотфильтрованная попытка.
- Критика: Затем агент меняет роли и становится собственным критиком. Он анализирует черновик на предмет недостатков, задавая такие вопросы, как «Это правильно?», «Это эффективно?» или «Что я упускаю?».
- Уточнение: В заключение, проведя собственную критику, агент генерирует окончательную, улучшенную версию результата, напрямую устраняя обнаруженные недостатки.
Прежде чем создавать логику агента, необходимо определить структуры данных, с которыми он будет работать. Использование моделей Pydantic — отличный способ заставить LLM выдавать чистые, структурированные JSON-данные, что крайне важно для многоэтапного процесса, где выходные данные одного этапа становятся входными данными для следующего.
prompt = f"""Вы — опытный программист на Python, которому поручено доработать фрагмент кода на основе критики.
Ваша цель — переписать исходный код, внедрив все предложенные улучшения из критики.
**Исходный код:**
```python
{draft_code}
``` {data-source-line= "115" }
**Критика и предложения:**
{critique_suggestions}
Пожалуйста, предоставьте окончательный, доработанный код и краткое описание внесенных вами изменений.
"""
refined_code = refiner_llm.invoke(prompt)
return { "refined_code" : refined_code.model_dump()}
Итак, у нас есть три логических элемента. Теперь нам нужно объединить их в рабочий процесс. Вот тут-то и пригодится LangGraph. Мы определим параметры, stateкоторые будут передаваться между нашими узлами, а затем построим сам граф.
class ReflectionState ( TypedDict ):
"""Представляет состояние нашего графа отражений."""
user_request: str
draft: Optional [ dict ]
critique: Optional [ dict ]
refined_code: Optional [ dict ]
# Инициализация нового графа состояний
graph_builder = StateGraph(ReflectionState)
# Добавление узлов в граф
graph_builder.add_node( "generator" , generator_node)
graph_builder.add_node( "critic" , critic_node)
graph_builder.add_node( "refiner" , refiner_node)
# Определение ребер рабочего процесса как простой линейной последовательности
graph_builder.set_entry_point( "generator" )
graph_builder.add_edge( "generator" , "critic" )
graph_builder.add_edge( "critic" , "refiner" )
graph_builder.add_edge( "refiner" , END)
# Компиляция графа в исполняемое приложение
reflection_app = graph_builder.compile ( )
Поток представляет собой простую прямую линию: generator-> critic-> refiner. Это классический шаблон отражения, и теперь мы готовы его протестировать.

Для проверки этого алгоритма мы рассмотрим классическую задачу программирования, где наивная первая попытка часто оказывается неэффективной: нахождение n-го числа Фибоначчи . Это идеальный тестовый пример, поскольку простое рекурсивное решение легко написать, но оно вычислительно затратно, что оставляет много возможностей для улучшения.
user_request = "Напишите функцию на Python для нахождения n-го числа Фибоначчи."
initial_input = { "user_request" : user_request}
console. print ( f"[bold cyan]🚀 Запуск рабочего процесса рефлексии для запроса:[/bold cyan] ' {user_request} '\n" )
# Передача результатов и сохранение конечного состояния
final_state = None
for state_update in reflection_app.stream(initial_input, stream_mode= "values" ):
final_state = state_update
console. print ( "\n[bold green]✅ Рабочий процесс рефлексии завершен![/bold green]" )
Давайте посмотрим на фотографии «до» и «после» , чтобы увидеть, что сделал наш агент.
--- ### Первоначальный вариант ---
Пояснение: Эта функция использует рекурсивный подход для вычисления n-го числа Фибоначчи... Этот подход неэффективен для больших значений n из-за повторяющихся вычислений...
1 def fibonacci(n):
2 if n <= 0:
3 return 0
4 elif n == 1:
5 return 1
6 else :
7 return fibonacci(n-1) + fibonacci(n-2)
--- ### Критика ---
Резюме: Функция содержит потенциальные ошибки и неэффективность. Ее следует переработать для обработки отрицательных входных данных и улучшения временной сложности.
Предлагаемые улучшения:
- Функция некорректно обрабатывает отрицательные числа.
- Функция имеет высокую временную сложность из-за повторяющихся вычислений. Рассмотрите возможность использования динамического программирования или мемоизации.
- Функция не соответствует соглашениям PEP 8...
--- ### Окончательный улучшенный код ---
Краткое описание улучшений: Исходный код был переработан для обработки отрицательных входных данных, улучшения временной сложности и соответствия соглашениям PEP 8.
1 def fibonacci(n):
2 "" " Вычисляет n-е число Фибоначчи." ""
3 if n < 0:
4 raise ValueError( "n должно быть неотрицательным целым числом" )
5 elif n == 0:
6 return 0
7 elif n == 1:
8 return 1
9 else :
10 fib = [0, 1]
11 for i in range(2, n + 1):
12 fib.append(fib[i-1] + fib[i-2])
13 return fib[n]
Первоначальный вариант представляет собой простую рекурсивную функцию, правильную, но ужасно неэффективную. Критик указывает на экспоненциальную сложность и другие проблемы. А доработанный код — это гораздо более умное и надежное итеративное решение. Это прекрасный пример того, как шаблон работает так, как задумано.
Чтобы сделать это более наглядным, давайте привлечем еще одного магистра права (LLM), который выступит в роли беспристрастного «судьи» и оценит как первоначальный вариант, так и окончательный код. Это позволит нам получить количественную оценку улучшения.
class CodeEvaluation ( BaseModel ):
"""Схема для оценки фрагмента кода."""
correctness_score: int = Field(description= "Оценка от 1 до 10, насколько код логически корректен." )
efficiency_score: int = Field(description= "Оценка от 1 до 10, насколько алгоритмически эффективен код." )
style_score: int = Field(description= "Оценка от 1 до 10, насколько стиль и читаемость кода соответствуют PEP 8." )
justification: str = Field(description= "Краткое обоснование оценок." )
def evaluate_code ( code_to_evaluate: str ):
prompt = f"""Вы — эксперт по оценке кода на Python. Оцените следующую функцию по шкале от 1 до 10 на корректность, эффективность и стиль. Предоставьте краткое обоснование.
Код:
```python
{code_to_evaluate}
```
"""
return judge_llm.invoke(prompt)
if final_state and 'draft' in final_state and 'refined_code' in final_state:
console. print ( "--- Оценка первоначального черновика ---" )
initial_draft_evaluation = evaluate_code(final_state[ 'draft' ][ 'code' ])
console. print (initial_draft_evaluation.model_dump()) # Исправлено: используйте .model_dump()
console. print ( "\n--- Оценка уточненного кода ---" )
refined_code_evaluation = evaluate_code(final_state[ 'refined_code' ][ 'refined_code' ])
console. print (refined_code_evaluation.model_dump()) # Исправлено: используйте .model_dump()
else :
console. print ( "[жирный красный]Ошибка: Невозможно выполнить оценку, поскольку `final_state` неполный.[/жирный красный]" )
Когда мы запускаем проверку на обеих версиях, результаты говорят сами за себя.
--- Оценка первоначального варианта ---
{
'correctness_score' : 2 ,
'efficiency_score' : 4 ,
'style_score' : 2 ,
'justification' : 'Функция имеет временную сложность O(2^n)...'
}
--- Оценка уточненного кода ---
{
'correctness_score' : 8 ,
'efficiency_score' : 6 ,
'style_score' : 9 ,
'justification' : 'Код корректен... он имеет временную сложность O(n)...'
}
Первоначальный вариант получил ужасные оценки, особенно по эффективности. Доработанный код демонстрирует колоссальный прогресс по всем параметрам.
Это дает нам неопровержимое доказательство того, что процесс рефлексии не просто изменил код, а сделал его несколько лучше.