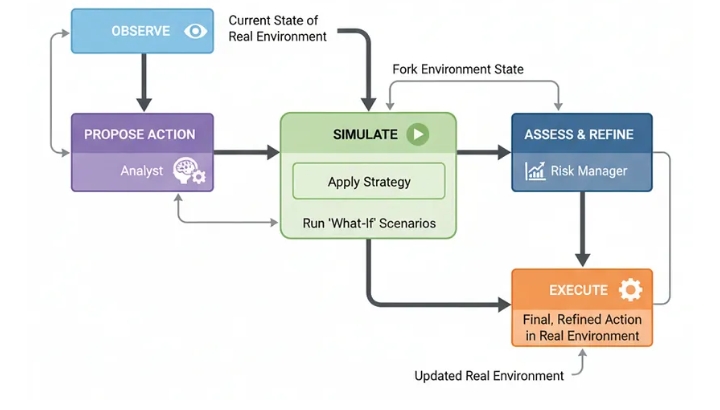
Симулятор (ментальная модель в контуре управления)
Агенты, подобные PEV, могут справиться с отказом инструмента и разработать новый план. Но все их планирование основано на предположении, что мир остается неизменным между шагами.
Что происходит в динамичной среде, такой как фондовый рынок, где ситуация постоянно меняется, а результат действия неопределен?
Архитектура симулятора , или ментальной модели в контуре управления , улучшает PEV, предлагаемую стратегию, в безопасной внутренней симуляции окружающего мира. Запуская сценарии «что если», система может увидеть вероятные последствия своих действий, уточнить план и только после этого принять более взвешенное решение в реальном мире.
Для любой системы искусственного интеллекта это важно там, где принятие решений с высокими ставками может привести к реальным, неопределенным последствиям. Вспомните робототехнику, финансовую торговлю или планирование лечения. Именно архитектура позволяет агенту «думать, прежде чем действовать» в самом конкретном смысле.
Всё начинается с…
simulated_market = state[ 'real_market' ].model_copy(deep= True )
initial_value = simulated_market.portfolio.value(simulated_market.price)
# Преобразуйте стратегию в конкретное действие для симуляции
if "buy" in strategy:
action = "buy"
# Агрессивно = 25% денежных средств, Осторожно = 10%
amount = (simulated_market.portfolio.cash * ( 0.25 if "aggressively" in strategy else 0.1 )) / simulated_market.price
elif "sell" in strategy:
action = "sell"
# Агрессивно = 25% акций, Осторожно = 10%
amount = simulated_market.portfolio.shares * ( 0.25 if "aggressively" in strategy else 0.1 )
else :
action = "hold"
amount = 0
# Запускаем симуляцию вперед
simulated_market.step(action, amount)
for _ in range (simulation_horizon - 1 ):
simulated_market.step( "hold" ) # Просто удерживаем после начального действия
final_value = simulated_market.portfolio.value(simulated_market.price)
results.append({ "sim_num" : i+ 1 , "initial_value" : initial_value, "final_value" : final_value, "return_pct" : (final_value - initial_value) / initial_value * 100 })
console. print ( "[cyan]Моделирование завершено. Результаты будут переданы менеджеру по рискам.[/cyan]" )
return { "simulation_results" : results}
def refine_and_decide_node ( state: AgentState ) -> Dict [ str , Any ]:
"""Анализирует результаты моделирования и принимает окончательное, уточненное решение."""
console.print ( "--- 🧠 Менеджер по рискам уточняет решение ---" )
results_summary ="\n" .join([ f"Sim {r[ 'sim_num' ]} : Initial=$ {r[ 'initial_value' ]: .2 f} , Final=$ {r[ 'final_value' ]: .2 f} , Return= {r[ 'return_pct' ]: .2 f} %" for r in state[ 'simulation_results' ]])
prompt = ChatPromptTemplate.from_template(
"Вы осторожный риск-менеджер. Ваш аналитик предложил стратегию. Вы провели симуляции для ее проверки. Основываясь на потенциальных результатах, примите окончательное, конкретное решение. Если результаты сильно варьируются или отрицательны, снизьте риск (например, купите/продайте меньше акций или удерживайте).\n\nПервоначальное предложение: {proposal}\n\nРезультаты симуляции:\n{results}\n\nРеальное состояние рынка:\n{market_state}"
)
decider_llm = llm.with_structured_output(FinalDecision)
chain = prompt | decider_llm
final_decision = chain.invoke({
"proposal" : state[ 'proposed_action' ].strategy,
"results" : results_summary,
"market_state" : state[ 'real_market' ].get_state_string()
})
console. print ( f"[green]Окончательное решение:[/green] {final_decision.action} {final_decision.amount: .0 f} акций. [italic]Причина: {final_decision.reasoning} [/italic]" )
return { "final_decision" : final_decision}
def execute_in_real_world_node ( state: AgentState ) -> Dict [ str , Any ]:
"""Выполняет окончательное решение в условиях реального рынка."""
console. print ( "--- 🚀 Выполнение в реальном мире ---" )
decision = state[ 'final_decision' ]
real_market = state[ 'real_market' ]
real_market.step(decision.action, decision.amount)
console.print ( f "[bold]Выполнение завершено. Новое состояние рынка:[/bold]\n {real_market.get_state_string()} " )
return { "real_market" : real_market}

Мысленная петля
Давайте запустим нашего агента на рынке на два «дня». Сначала мы дадим ему хорошие новости, чтобы посмотреть, как он воспользуется возможностью. Затем мы обрушим на него плохие новости, чтобы посмотреть, как он будет управлять рисками.
11:34:4811:34:50
real_market = MarketSimulator()
# --- Запуск 1-го дня: Появляются хорошие новости ---
real_market.market_news = "Ожидается положительный отчет о прибыли."
final_state_day1 = simulator_agent.invoke({ "real_market" : real_market})
# --- Запуск 2-го дня: Появляются плохие новости ---
real_market_day2 = final_state_day1[ 'real_market' ]
real_market_day2.market_news = "На рынок выходит новый конкурент."
final_state_day2 = simulator_agent.invoke({ "real_market" : real_market_day2})
Трассировка выполнения демонстрирует детальные, основанные на моделировании рассуждения агента.
--- День 1: Хорошие новости! ---
--- 🧐 Предложение аналитика ---
[жёлтый]Предложение:[/жёлтый] покупать агрессивно. [курсив]Причина: Положительный отчёт о прибыли — сильный бычий сигнал...[/курсив]
--- 🤖 Проведение симуляций ---
--- 🧠 Уточнение решения риск-менеджером ---
[зелёный]Окончательное решение:[/зелёный] купить 20 акций. [курсив]Причина: Симуляции подтверждают сильный восходящий тренд... Я совершу значительную, но не чрезмерную покупку...[/курсив]
--- 🚀 Реализация в реальном мире ---
--- День 2: Плохие новости! ---
--- 🧐 Предложение аналитика ---
[жёлтый]Предложение:[/жёлтый] продавать осторожно. [курсив]Причина: появление нового конкурента вносит значительную неопределенность...[/курсив]
--- 🤖 Проведение симуляций ---
--- 🧠 Уточнение решения риск-менеджером ---
[зеленый]Окончательное решение:[/зеленый] продать 5 акций. [курсив]Причина: симуляции показывают высокую степень дисперсии... Я снижу риск портфеля, продав 5 акций...[/курсив]
В первый день компания не просто купила акции; сначала она провела симуляцию и определила конкретный объем, который обеспечивал баланс риска и потенциальной прибыли. Во второй день она не просто в панике продала акции, а смоделировала неопределенность и приняла взвешенное решение сократить свою позицию.
Для формализации этого процесса наш магистр права, выступающий в роли судьи, должен оценивать качество принимаемых решений и управление рисками.
class DecisionQualityEvaluation ( BaseModel ):
decision_robustness_score: int = Field(description= "Оценка от 1 до 10, показывающая, насколько окончательное решение агента было подтверждено моделированием." )
risk_management_score: int = Field(description= "Оценка от 1 до 10, показывающая, насколько хорошо агент управлял рисками, особенно в ответ на меняющиеся новости." )
justification: str = Field(description= "Краткое обоснование оценок." )
При оценке, агент-симулятор получает высшие баллы за продуманный процесс работы.
--- Оценка решений агента симулятора ---
{
'decision_robustness_score': 6,
'risk_management_score': 9,
'justification': "Решения агента не были наивными реакциями, а были непосредственно основаны на надежном процессе моделирования. Он правильно определил возможность в первый день и соответствующим образом снизил риски во второй день, продемонстрировав сложный, основанный на данных подход к управлению рисками."
}
Используя «ментальную модель» мира для проверки своих действий…
Наш агент способен принимать более безопасные, разумные и взвешенные решения в динамичной среде.