Древо мыслей (ToT)
Метод PEV позволяет справиться с отказом инструмента и повторить попытку по новому плану. Однако само планирование остается линейным. Оно создает единый пошаговый план и следует ему.
Что происходит, когда проблема представляет собой не прямую дорогу, а скорее лабиринт с тупиками и множеством возможных путей?
Здесь вступает в дело архитектура « Древо мыслей» (Tree-of-Thoughts, ToT) . Вместо того чтобы генерировать единую линию рассуждений, агент ToT исследует множество путей одновременно. Он генерирует несколько возможных следующих шагов, оценивает их, отбрасывает неподходящие и продолжает исследовать наиболее перспективные ветви.
В крупных системах искусственного интеллекта технология ToT помогает решать сложные задачи, такие как планирование маршрутов, составление расписаний или непростые головоломки.
Вот как работает обычный процесс обучения тренеров…
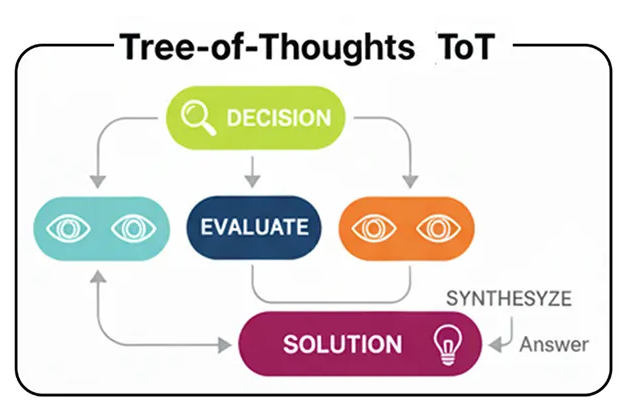
Процесс TOT (Создано компанией...)
Фарид Хан
)
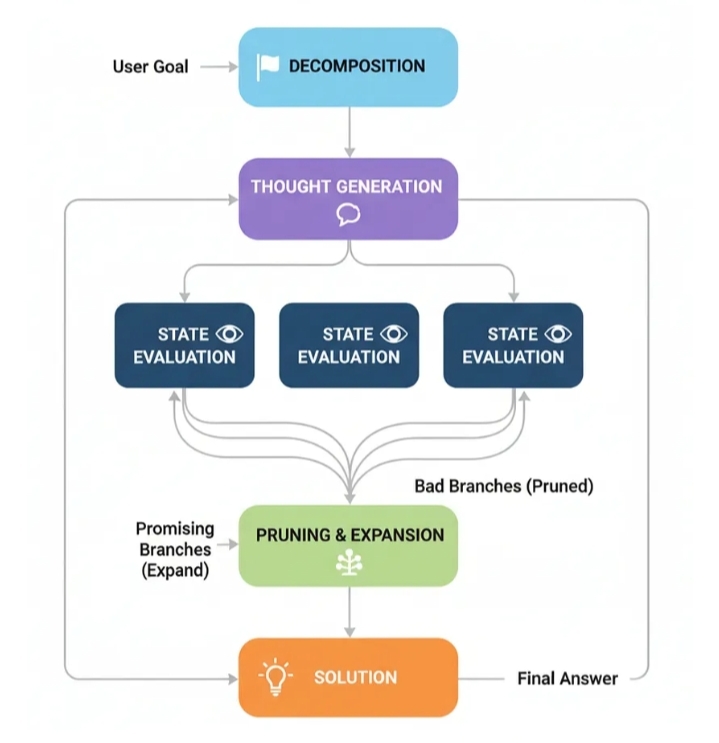
Декомпозиция: Проблема разбивается на ряд шагов или «мыслей».
Генерация мыслей: Для текущего состояния агент генерирует несколько потенциальных следующих шагов. Это создает ветви нашего «дерева мыслей».
Оценка состояния: Каждый новый потенциальный шаг оценивается критиком или функцией проверки. Эта проверка определяет, является ли ход допустимым, идет ли он навстречу прогрессу или же это просто движение по кругу.
Обрезка и расширение: Затем агент «обрезает» плохие ветви (недействительные или бесперспективные) и продолжает процесс с оставшихся хороших ветвей.
Решение: Этот процесс продолжается до тех пор, пока одна из ветвей не достигнет конечной цели.
Чтобы продемонстрировать ToT, нам нужна задача, которую нельзя решить по прямой линии, — головоломка «Волк, Коза и Капуста», позволяющая переправиться через реку. Она идеально подходит, поскольку требует неочевидных ходов (например, возвращения чего-либо обратно) и имеет недопустимые состояния, которые могут поставить в тупик простой логический механизм.
Сначала мы определим правила головоломки, используя пидантическую модель для состояния и функцию проверки корректности (чтобы ничего не было съедено).
class PuzzleState ( BaseModel ):
"Представляет состояние головоломки "Волк, Коза и Капуста."
left_bank: set [ str ] = Field(default_factory= lambda : { "wolf" , "goat" , "cabbage" })
right_bank: set [ str ] = Field(default_factory= set )
boat_location: str = "left"
move_description: str = "Начальное состояние."
def is_valid ( self ) -> bool :
"""Проверяет, является ли текущее состояние допустимым."""
# Проверяем левый берег на наличие недопустимых пар, если лодка находится справа.
if self.boat_location == "right" :
if "wolf" in self.left_bank and "goat" in self.left_bank: return False
if "goat" in self.left_bank and "cabbage" in self.left_bank: return False
# Проверяем правый берег на наличие недопустимых пар, если лодка находится слева.
if self.boat_location == "left" :
if "wolf" in self.right_bank and "goat" in self.right_bank: return False
if "goat" in self.right_bank and "cabbage" in self.right_bank: return False
return True
def is_goal ( self ) -> bool :
"""Проверяет, выиграли ли мы."""
return self.right_bank == { "wolf" , "коза" , "капуста" }
# Делаем состояние хешируемым, чтобы мы могли обнаруживать циклы
def __hash__ ( self ):
return hash (( frozenset (self.left_bank), frozenset (self.right_bank), self.boat_location))
Теперь перейдём к сути агента ToT. Состояние нашего графа будет содержать все активные пути в нашем дереве мыслей. Узел expand_pathsбудет генерировать новые ветви, а также prune_pathsобрезать дерево, удаляя все пути, которые заходят в тупик или образуют замкнутый круг.
class ToTState ( TypedDict ):
problem_description: str
active_paths: List [ List [PuzzleState]] # Это наше "древовидное"
решение: Optional [ List [PuzzleState]]
def expand_paths ( state: ToTState ) -> Dict [ str , Any ]:
"""Генератор мыслей. Расширяет каждый активный путь всеми допустимыми следующими ходами."""
console. print ( "--- Расширение путей ---" )
new_paths = []
for path in state[ 'active_paths' ]:
last_state = path[- 1 ]
# Получаем все допустимые следующие состояния из текущего состояния
possible_next_states = get_possible_moves(last_state) # Предполагая, что get_possible_moves определен
for next_state in possible_next_states:
new_paths.append(path + [next_state])
console. print ( f"[cyan]Расширено до { len (new_paths)} потенциальных путей.[/cyan]" )
return { "active_paths" : new_paths}
def prune_paths ( state: ToTState ) -> Dict [ str , Any ]:
"""Оценщик состояний. Удаляет недопустимые пути или пути, содержащие циклы."""
console.print ( "--- Удаление путей ---" )
pruned_paths = []
for path in state[ 'active_paths' ]:
# Проверка на циклы: если последнее состояние уже встречалось в пути
if path[ -1 ] in path[:- 1 ]:
continue # Найден цикл, удаляем этот путь
pruned_paths.append(path)
console. print ( f"[green]Сокращено до { len (pruned_paths)} допустимых, нециклических путей.[/green]" )
return { "active_paths" : pruned_paths}
# ... (соединение графа с условным ребром, проверяющим наличие решения) ...
workflow = StateGraph(ToTState)
workflow.add_node( "expand"
workflow.add_node( "prune" , prune_paths )

Архитектура ToT (создана)
Фарид Хан
)
Давайте запустим нашего агента ToT на этой головоломке. Простой агент, использующий метод «цепочки мыслей», мог бы решить её, если бы уже сталкивался с ней, но он лишь вспоминает решение. Наш агент ToT найдёт решение посредством систематического поиска.
проблема = "Фермер хочет пересечь реку с волком, козой и капустой..." console.print
( " --- 🌳 Запущен агент "Древо мыслей" ---" ) final_state = tot_agent.invoke({ "problem_description" : problem}, { "recursion_limit" : 15 }) console.print ( " \n--- ✅ Решение агента ToT ---" )
Траектория вывода показывает работу агента, методично исследующего головоломку.
--- Расширение путей ---
[голубой]Расширено до 1 потенциального пути.[/голубой]
--- Сокращение путей ---
[зеленый]Сокращено до 1 допустимого, нециклического пути.[/зеленый]
--- Расширение путей ---
[голубой]Расширено до 2 потенциальных путей.[/голубой]
--- Сокращение путей ---
[зеленый]Сокращено до 2 допустимых, нециклических путей.[/зеленый]
...
[жирный зеленый]Решение найдено![/жирный зеленый]
--- ✅ Решение агента ToT ---
1. Начальное состояние.
2. Переместить козу на правый берег.
3. Переместить пустую лодку на левый берег.
4. Переместить волка на правый берег.
5. Переместить козу на левый берег.
6. Переместить капусту на правый берег.
7. Переместить пустую лодку на левый берег.
8. Переместить козу на правый берег.
Агент нашел правильное решение из 8 шагов! Он не просто угадал; он систематически исследовал возможные варианты, отбрасывал неверные и нашел путь, который гарантированно оказался правильным. В этом и заключается сила ToT (Tool-to-T).
Для формализации этого вопроса мы будем использовать специалиста по праву в качестве судьи, который будет оценивать качество процесса рассуждений.
class ReasoningEvaluation ( BaseModel ):
"""Схема для оценки процесса рассуждений агента."""
solution_correctness_score: int = Field(description= "Оценка от 1 до 10, указывающая на правильность и корректность окончательного решения." )
reasoning_robustness_score: int = Field(description= "Оценка от 1 до 10, указывающая на надежность процесса рассуждений агента. Высокая оценка означает, что он систематически исследовал проблему, низкая — что он просто угадывал." )
justification: str = Field(description= "Краткое обоснование оценок." )
Простой агент, использующий метод «цепочки мыслей», может получить высокий балл за правильность, если ему повезет, но его показатель устойчивости будет низким. Наш же агент, использующий этот метод, получает высшие оценки.
--- Оценка процесса работы агента ToT ---
{
'solution_correctness_score' : 8 ,
'reasoning_robustness_score' : 9 ,
'justification' : "Процесс работы агента был абсолютно надежным. Он не просто давал ответ; он систематически исследовал дерево возможных вариантов, отсеивал неверные пути и гарантировал правильное решение. Это гораздо более надежный метод, чем однократное угадывание."
}
Мы видим, что агент ToT работает хорошо не случайно, а потому что его поиск является надежным.
Это делает его лучшим выбором для задач, требующих высокой надежности.